 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel selection for deep audio source separation via clustering analysis
Paper and Code

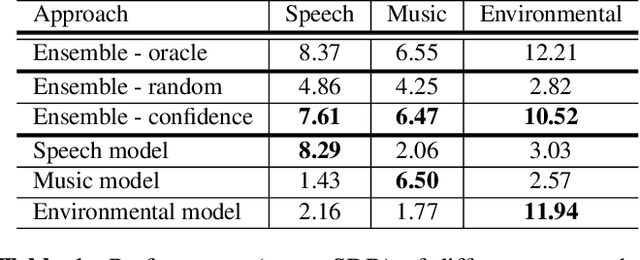
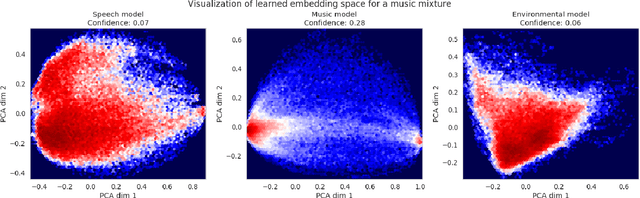
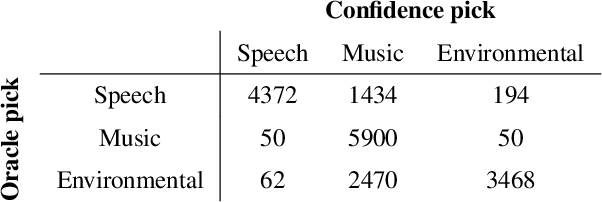
Audio source separation is the process of separating a mixture (e.g. a pop band recording) into isolated sounds from individual sources (e.g. just the lead vocals). Deep learning models are the state-of-the-art in source separation, given that the mixture to be separated is similar to the mixtures the deep model was trained on. This requires the end user to know enough about each model's training to select the correct model for a given audio mixture. In this work, we automate selection of the appropriate model for an audio mixture. We present a confidence measure that does not require ground truth to estimate separation quality, given a deep model and audio mixture. We use this confidence measure to automatically select the model output with the best predicted separation quality. We compare our confidence-based ensemble approach to using individual models with no selection, to an oracle that always selects the best model and to a random model selector. Results show our confidence-based ensemble significantly outperforms the random ensemble over general mixtures and approaches oracle performance for music mixtures.