 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat does BERT Learn from Multiple-Choice Reading Comprehension Datasets?
Paper and Code

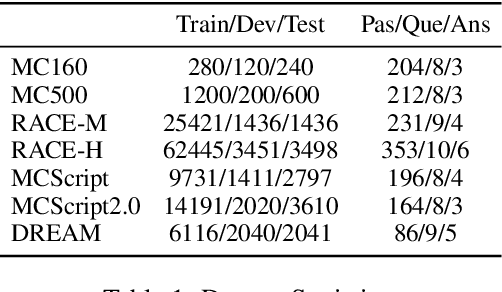
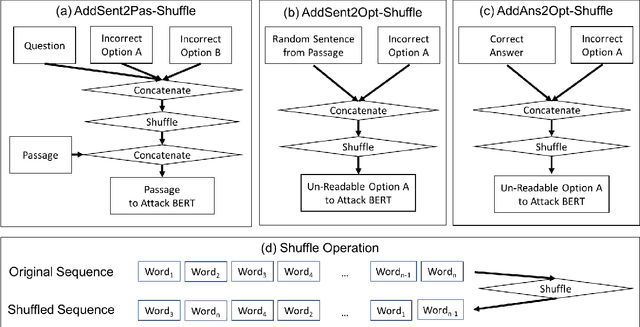
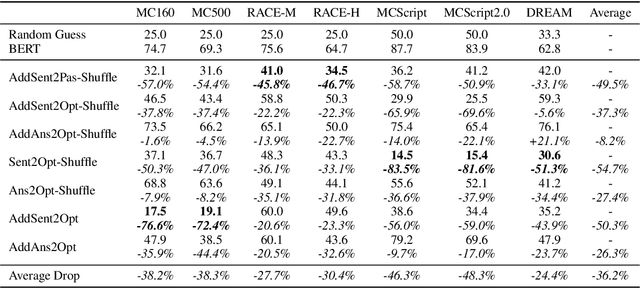
Multiple-Choice Reading Comprehension (MCRC) requires the model to read the passage and question, and select the correct answer among the given options. Recent state-of-the-art models have achieved impressive performance on multiple MCRC datasets. However, such performance may not reflect the model's true ability of language understanding and reasoning. In this work, we adopt two approaches to investigate what BERT learns from MCRC datasets: 1) an un-readable data attack, in which we add keywords to confuse BERT, leading to a significant performance drop; and 2) an un-answerable data training, in which we train BERT on partial or shuffled input. Under un-answerable data training, BERT achieves unexpectedly high performance. Based on our experiments on the 5 key MCRC datasets - RACE, MCTest, MCScript, MCScript2.0, DREAM - we observe that 1) fine-tuned BERT mainly learns how keywords lead to correct prediction, instead of learning semantic understanding and reasoning; and 2) BERT does not need correct syntactic information to solve the task; 3) there exists artifacts in these datasets such that they can be solved even without the full context.