 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping deep music separation from primitive auditory grouping principles
Paper and Code
Oct 23, 2019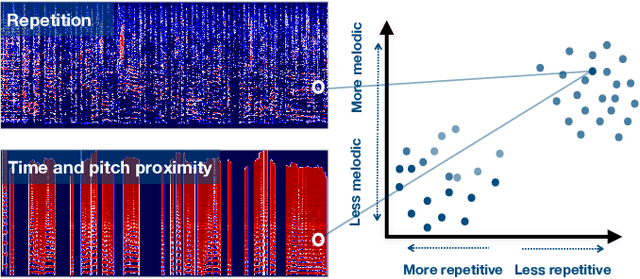
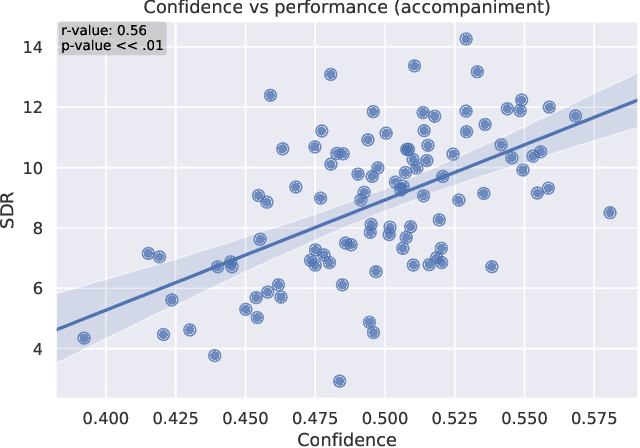
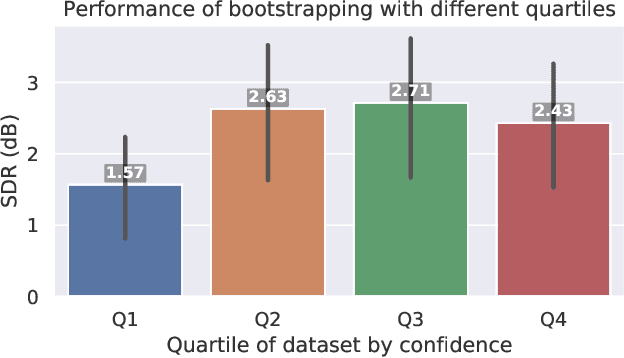
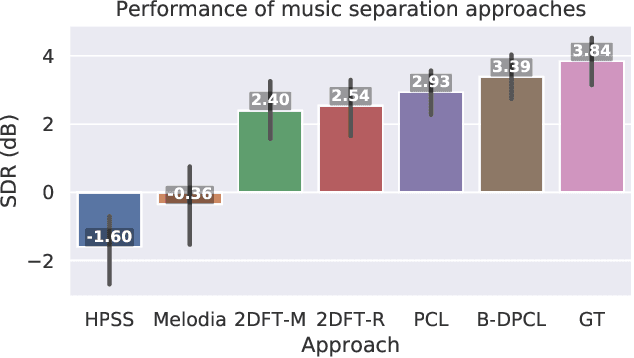
Separating an audio scene such as a cocktail party into constituent, meaningful components is a core task in computer audition. Deep networks are the state-of-the-art approach. They are trained on synthetic mixtures of audio made from isolated sound source recordings so that ground truth for the separation is known. However, the vast majority of available audio is not isolated. The brain uses primitive cues that are independent of the characteristics of any particular sound source to perform an initial segmentation of the audio scene. We present a method for bootstrapping a deep model for music source separation without ground truth by using multiple primitive cues. We apply our method to train a network on a large set of unlabeled music recordings from YouTube to separate vocals from accompaniment without the need for ground truth isolated sources or artificial training mixtures.