 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Distributed Accelerated Stochastic Gradient Methods for Multi-Agent Networks
Paper and Code
Nov 15, 2019

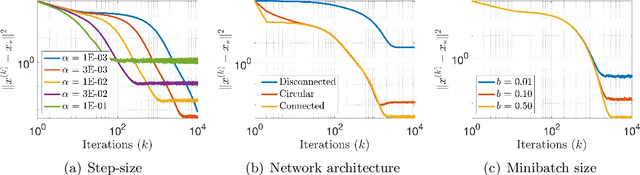
We study distributed stochastic gradient (D-SG) method and its accelerated variant (D-ASG) for solving decentralized strongly convex stochastic optimization problems where the objective function is distributed over several computational units, lying on a fixed but arbitrary connected communication graph, subject to local communication constraints where noisy estimates of the gradients are available. We develop a framework which allows to choose the stepsize and the momentum parameters of these algorithms in a way to optimize performance by systematically trading off the bias, variance, robustness to gradient noise and dependence to network effects. When gradients do not contain noise, we also prove that distributed accelerated methods can \emph{achieve acceleration}, requiring $\mathcal{O}(\kappa \log(1/\varepsilon))$ gradient evaluations and $\mathcal{O}(\kappa \log(1/\varepsilon))$ communications to converge to the same fixed point with the non-accelerated variant where $\kappa$ is the condition number and $\varepsilon$ is the target accuracy. To our knowledge, this is the first acceleration result where the iteration complexity scales with the square root of the condition number in the context of \emph{primal} distributed inexact first-order methods. For quadratic functions, we also provide finer performance bounds that are tight with respect to bias and variance terms. Finally, we study a multistage version of D-ASG with parameters carefully varied over stages to ensure exact $\mathcal{O}(-k/\sqrt{\kappa})$ linear decay in the bias term as well as optimal $\mathcal{O}(\sigma^2/k)$ in the variance term. We illustrate through numerical experiments that our approach results in practical algorithms that are robust to gradient noise and that can outperform existing methods.