 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Navigate from Simulation via Spatial and Semantic Information Synthesis with Noise Model Embedding
Paper and Code
Nov 12, 2019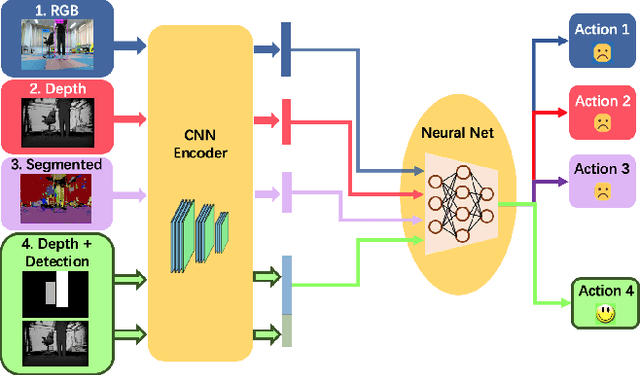
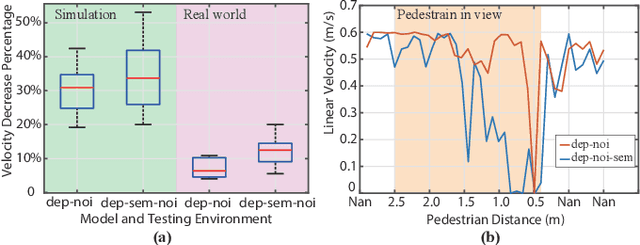

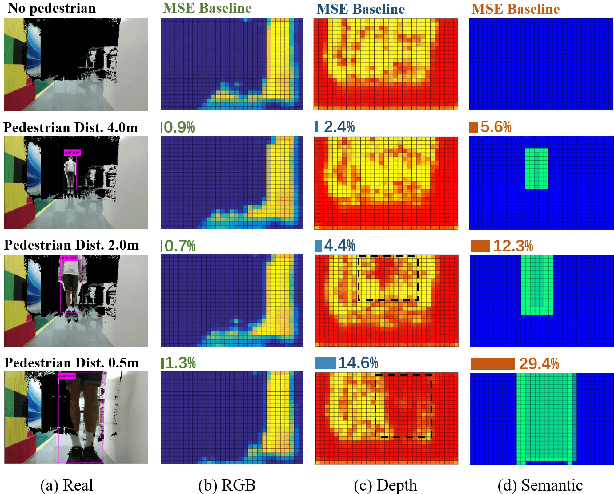
While training an end-to-end navigation network in the real world is usually of high cost, simulation provides a safe and cheap environment in this training stage. However, training neural network models in simulation brings up the problem of how to effectively transfer the model from simulation to the real world (sim-to-real). In this work, we regard the environment representation as a crucial element in this transfer process and propose a visual information pyramid (VIP) model to systematically investigate a practical environment representation. A novel representation composed of spatial and semantic information synthesis is then established accordingly, where noise model embedding is particularly considered. To explore the effectiveness of this representation, we compared the performance with representations popularly used in the literature in both simulated and real-world scenarios. Results suggest that our environment representation stands out. Furthermore, an analysis on the feature map is implemented to investigate the effectiveness through inner reaction, which could be irradiative for future researches on end-to-end navigation.