 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeMare: Asynchronous Pipeline Parallel DNN Training
Paper and Code
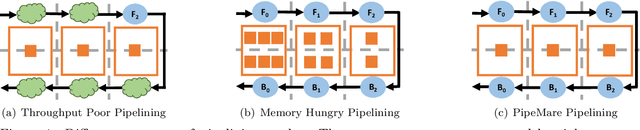

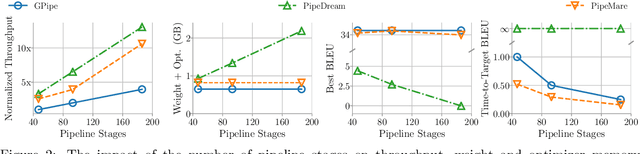
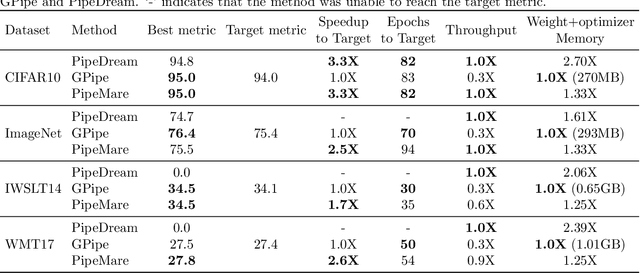
Recently there has been a flurry of interest around using pipeline parallelism while training neural networks. Pipeline parallelism enables larger models to be partitioned spatially across chips and within a chip, leading to both lower network communication and overall higher hardware utilization. Unfortunately, to preserve statistical efficiency, existing pipeline-parallelism techniques sacrifice hardware efficiency by introducing bubbles into the pipeline and/or incurring extra memory costs. In this paper, we investigate to what extent these sacrifices are necessary. Theoretically, we derive a simple but robust training method, called PipeMare, that tolerates asynchronous updates during pipeline-parallel execution. Using this, we show empirically, on a ResNet network and a Transformer network, that PipeMare can achieve final model qualities that match those of synchronous training techniques (at most 0.9% worse test accuracy and 0.3 better test BLEU score) while either using up to 2.0X less weight and optimizer memory or being up to 3.3X faster than other pipeline parallel training techniques. To the best of our knowledge we are the first to explore these techniques and fine-grained pipeline parallelism (e.g. the number of pipeline stages equals to the number of layers) during neural network training.