 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Visual Task Adaptation Benchmark
Paper and Code
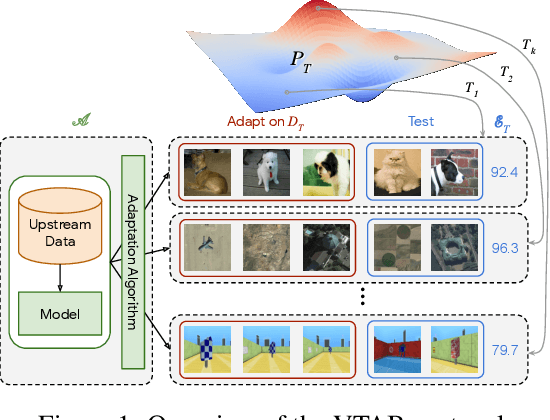
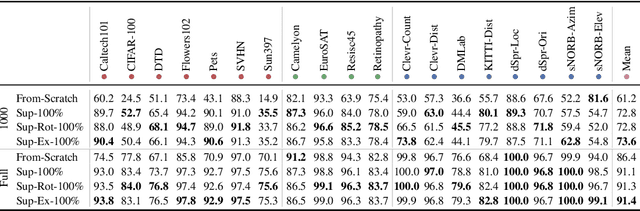
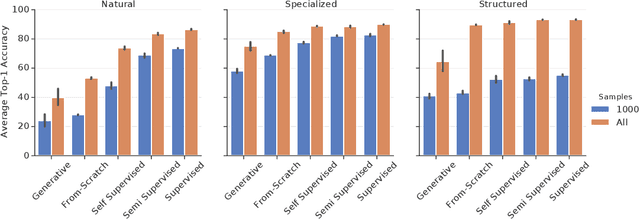
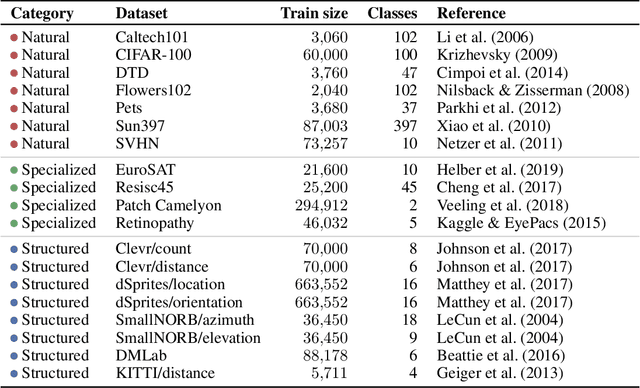
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?