 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Value Model Predictive Control
Paper and Code
Oct 08, 2019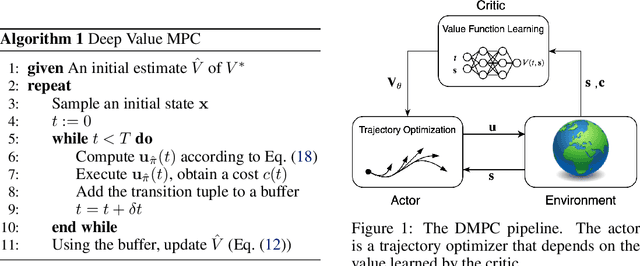
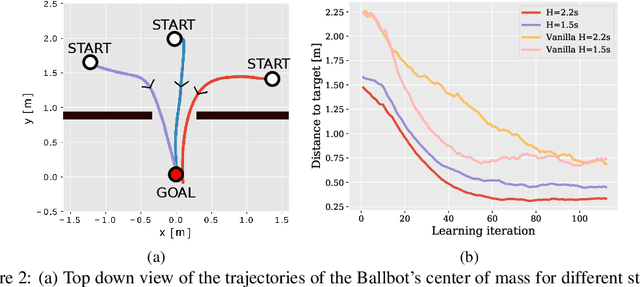


In this paper, we introduce an actor-critic algorithm called Deep Value Model Predictive Control (DMPC), which combines model-based trajectory optimization with value function estimation. The DMPC actor is a Model Predictive Control (MPC) optimizer with an objective function defined in terms of a value function estimated by the critic. We show that our MPC actor is an importance sampler, which minimizes an upper bound of the cross-entropy to the state distribution of the optimal sampling policy. In our experiments with a Ballbot system, we show that our algorithm can work with sparse and binary reward signals to efficiently solve obstacle avoidance and target reaching tasks. Compared to previous work, we show that including the value function in the running cost of the trajectory optimizer speeds up the convergence. We also discuss the necessary strategies to robustify the algorithm in practice.