 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyenet: Attention based Convolutional Encoder-Decoder Network for Eye Region Segmentation
Paper and Code
Oct 08, 2019
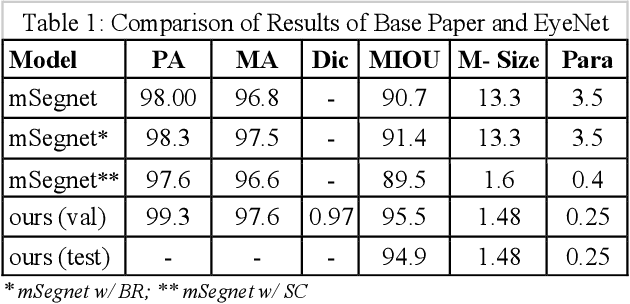
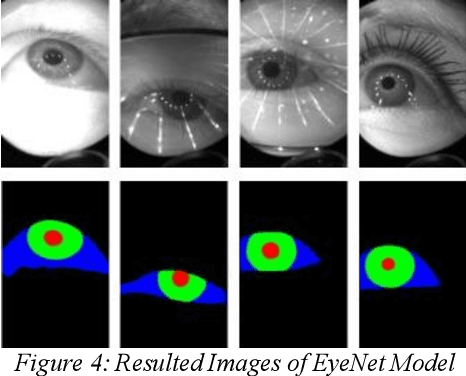
With the immersive development in the field of augmented and virtual reality, accurate and speedy eye-tracking is required. Facebook Research has organized a challenge, named OpenEDS Semantic Segmentation challenge for per-pixel segmentation of the key eye regions: the sclera, the iris, the pupil, and everything else (background). There are two constraints set for the participants viz MIOU and the computational complexity of the model. More recently, researchers have achieved quite a good result using the convolutional neural networks (CNN) in segmenting eyeregions. However, the environmental challenges involved in this task such as low resolution, blur, unusual glint and, illumination, off-angles, off-axis, use of glasses and different color of iris region hinder the accuracy of segmentation. To address the challenges in eye segmentation, the present work proposes a robust and computationally efficient attention-based convolutional encoder-decoder network for segmenting all the eye regions. Our model, named EyeNet, includes modified residual units as the backbone, two types of attention blocks and multi-scale supervision for segmenting the aforesaid four eye regions. Our proposed model achieved a total score of 0.974(EDS Evaluation metric) on test data, which demonstrates superior results compared to the baseline methods.