 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Disentanglement of Neural Networks by Extracting Class-Specific Subnetwork
Paper and Code
Oct 07, 2019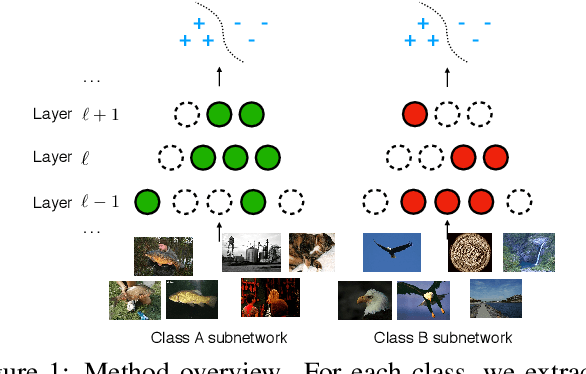
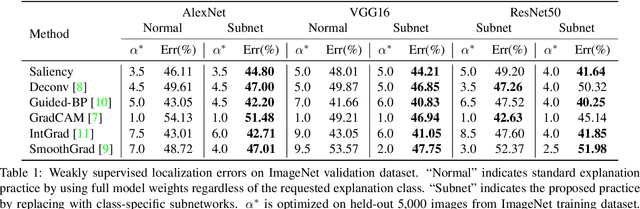
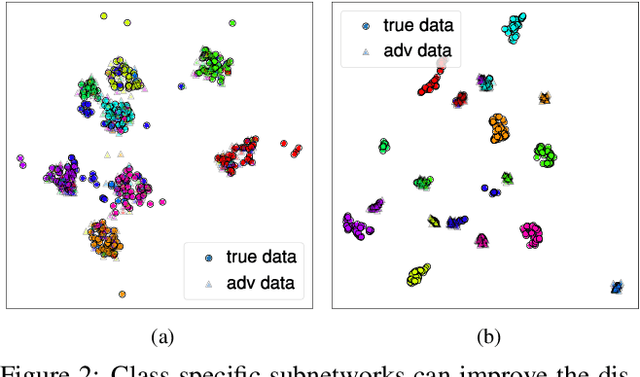
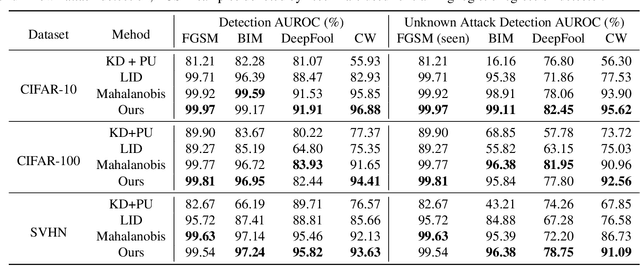
We propose a novel perspective to understand deep neural networks in an interpretable disentanglement form. For each semantic class, we extract a class-specific functional subnetwork from the original full model, with compressed structure while maintaining comparable prediction performance. The structure representations of extracted subnetworks display a resemblance to their corresponding class semantic similarities. We also apply extracted subnetworks in visual explanation and adversarial example detection tasks by merely replacing the original full model with class-specific subnetworks. Experiments demonstrate that this intuitive operation can effectively improve explanation saliency accuracy for gradient-based explanation methods, and increase the detection rate for confidence score-based adversarial example detection methods.