 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Deception in Political Debates Using Acoustic and Textual Features
Paper and Code

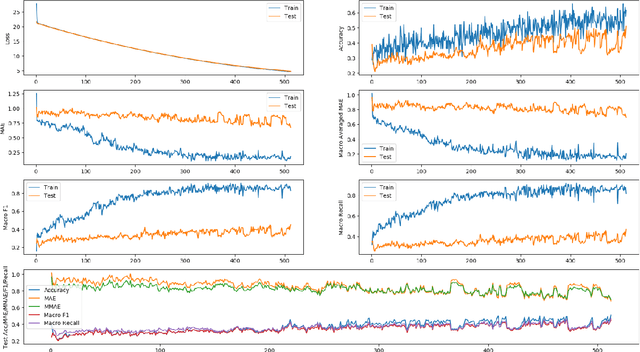
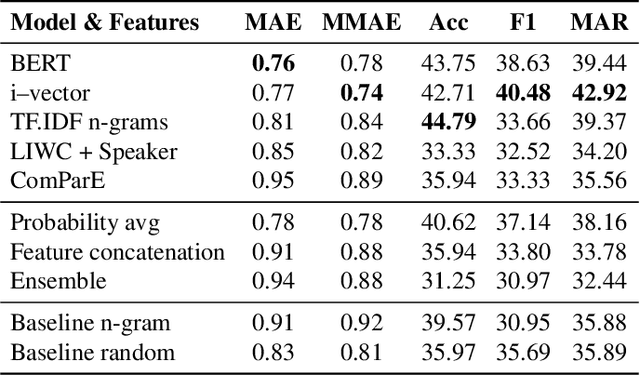
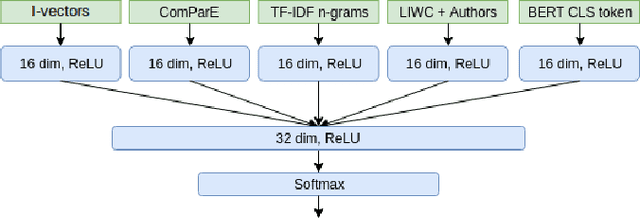
We present work on deception detection, where, given a spoken claim, we aim to predict its factuality. While previous work in the speech community has relied on recordings from staged setups where people were asked to tell the truth or to lie and their statements were recorded, here we use real-world political debates. Thanks to the efforts of fact-checking organizations, it is possible to obtain annotations for statements in the context of a political discourse as true, half-true, or false. Starting with such data from the CLEF-2018 CheckThat! Lab, which was limited to text, we performed alignment to the corresponding videos, thus producing a multimodal dataset. We further developed a multimodal deep-learning architecture for the task of deception detection, which yielded sizable improvements over the state of the art for the CLEF-2018 Lab task 2. Our experiments show that the use of the acoustic signal consistently helped to improve the performance compared to using textual and metadata features only, based on several different evaluation measures. We release the new dataset to the research community, hoping to help advance the overall field of multimodal deception detection.