 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-native Speaker Verification for Spoken Language Assessment
Paper and Code
Sep 30, 2019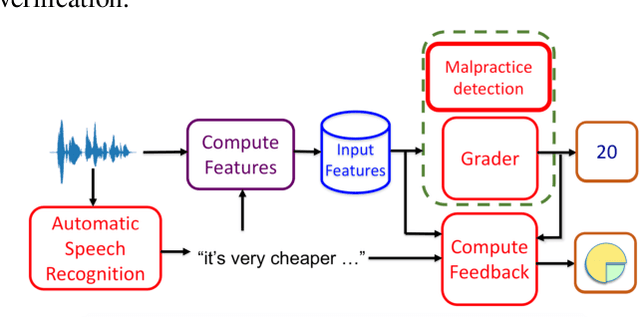


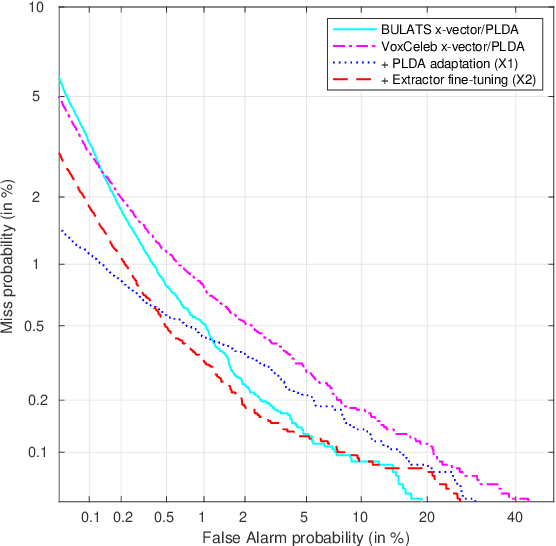
Automatic spoken language assessment systems are becoming more popular in order to handle increasing interests in second language learning. One challenge for these systems is to detect malpractice. Malpractice can take a range of forms, this paper focuses on detecting when a candidate attempts to impersonate another in a speaking test. This form of malpractice is closely related to speaker verification, but applied in the specific domain of spoken language assessment. Advanced speaker verification systems, which leverage deep-learning approaches to extract speaker representations, have been successfully applied to a range of native speaker verification tasks. These systems are explored for non-native spoken English data in this paper. The data used for speaker enrolment and verification is mainly taken from the BULATS test, which assesses English language skills for business. Performance of systems trained on relatively limited amounts of BULATS data, and standard large speaker verification corpora, is compared. Experimental results on large-scale test sets with millions of trials show that the best performance is achieved by adapting the imported model to non-native data. Breakdown of impostor trials across different first languages (L1s) and grades is analysed, which shows that inter-L1 impostors are more challenging for speaker verification systems.