 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$α^α$-Rank: Scalable Multi-agent Evaluation through Evolution
Paper and Code
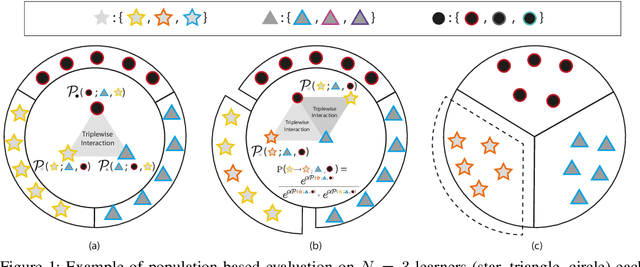
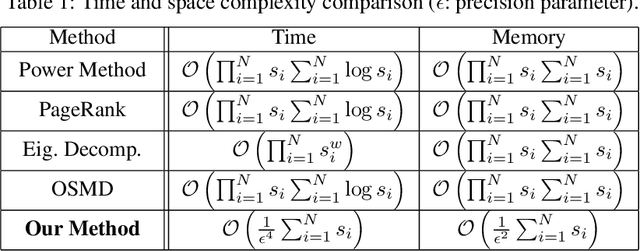
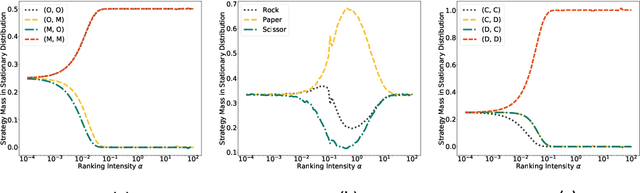
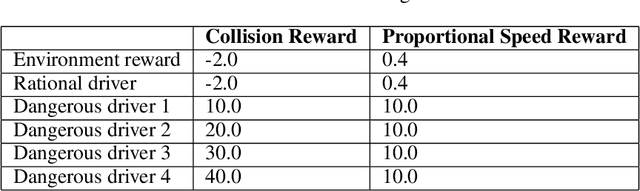
Although challenging, strategy profile evaluation in large connected learner networks is crucial for enabling the next wave of machine learning applications. Recently, $\alpha$-Rank, an evolutionary algorithm, has been proposed as a solution for ranking joint policy profiles in multi-agent systems. $\alpha$-Rank claimed scalability through a polynomial time implementation with respect to the total number of pure strategy profiles. In this paper, we formally prove that such a claim is not grounded. In fact, we show that $\alpha$-Rank exhibits an exponential complexity in number of agents, hindering its application beyond a small finite number of joint profiles. Realizing such a limitation, we contribute by proposing a scalable evaluation protocol that we title $\alpha^{\alpha}$-Rank. Our method combines evolutionary dynamics with stochastic optimization and double oracles for \emph{truly} scalable ranking with linear (in number of agents) time and memory complexities. Our contributions allow us, for the first time, to conduct large-scale evaluation experiments of multi-agent systems, where we show successful results on large joint strategy profiles with sizes in the order of $\mathcal{O}(2^{25})$ (i.e., $\approx \text{$33$ million strategies}$) -- a setting not evaluable using current techniques.