 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemGuard: Defending against Black-Box Membership Inference Attacks via Adversarial Examples
Paper and Code
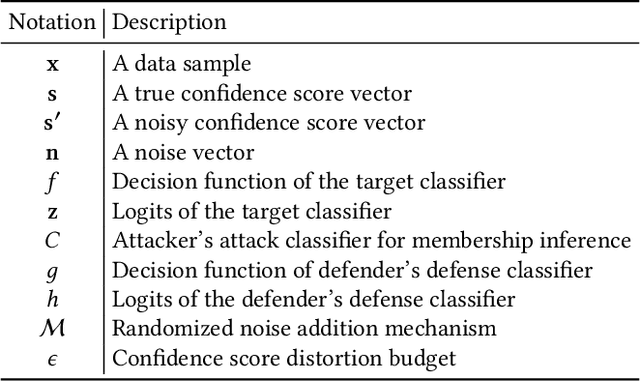
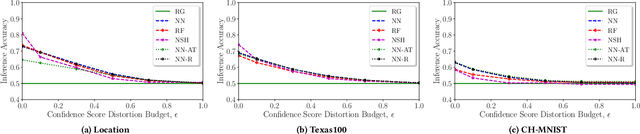
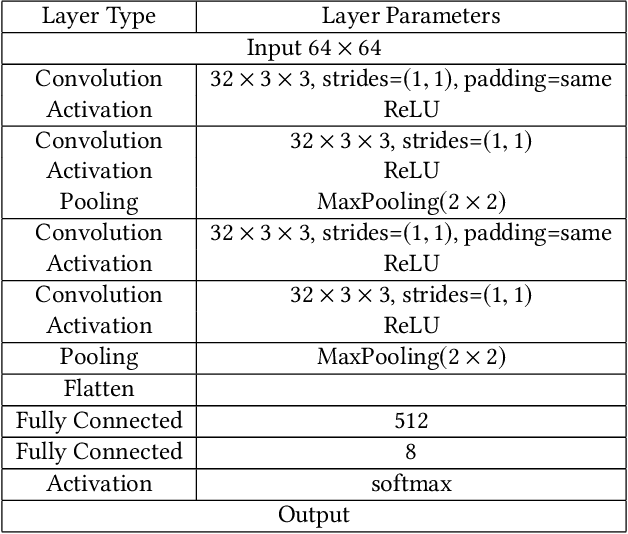
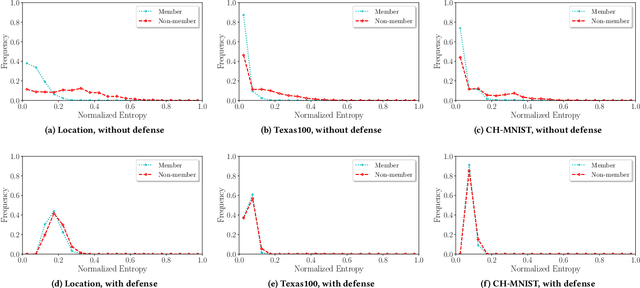
In a membership inference attack, an attacker aims to infer whether a data sample is in a target classifier's training dataset or not. Specifically, given a black-box access to the target classifier, the attacker trains a binary classifier, which takes a data sample's confidence score vector predicted by the target classifier as an input and predicts the data sample to be a member or non-member of the target classifier's training dataset. Membership inference attacks pose severe privacy and security threats to the training dataset. Most existing defenses leverage differential privacy when training the target classifier or regularize the training process of the target classifier. These defenses suffer from two key limitations: 1) they do not have formal utility-loss guarantees of the confidence score vectors, and 2) they achieve suboptimal privacy-utility tradeoffs. In this work, we propose MemGuard, the first defense with formal utility-loss guarantees against black-box membership inference attacks. Instead of tampering the training process of the target classifier, MemGuard adds noise to each confidence score vector predicted by the target classifier. Our key observation is that attacker uses a classifier to predict member or non-member and classifier is vulnerable to adversarial examples. Based on the observation, we propose to add a carefully crafted noise vector to a confidence score vector to turn it into an adversarial example that misleads the attacker's classifier. Our experimental results on three datasets show that MemGuard can effectively defend against membership inference attacks and achieve better privacy-utility tradeoffs than existing defenses. Our work is the first one to show that adversarial examples can be used as defensive mechanisms to defend against membership inference attacks.