 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic scene analysis with multi-head attention networks
Paper and Code

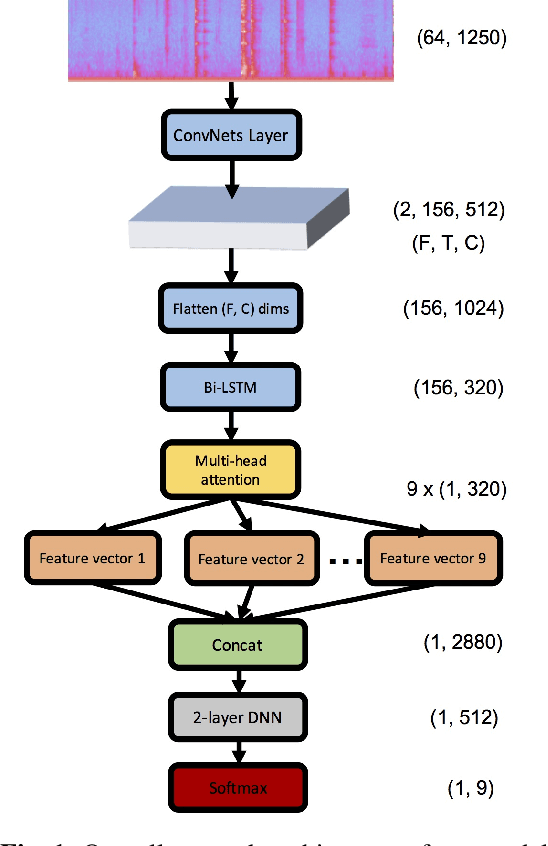
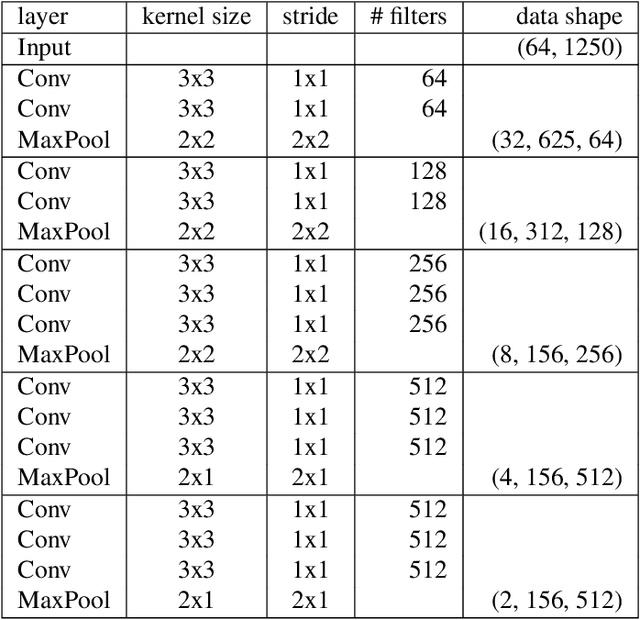
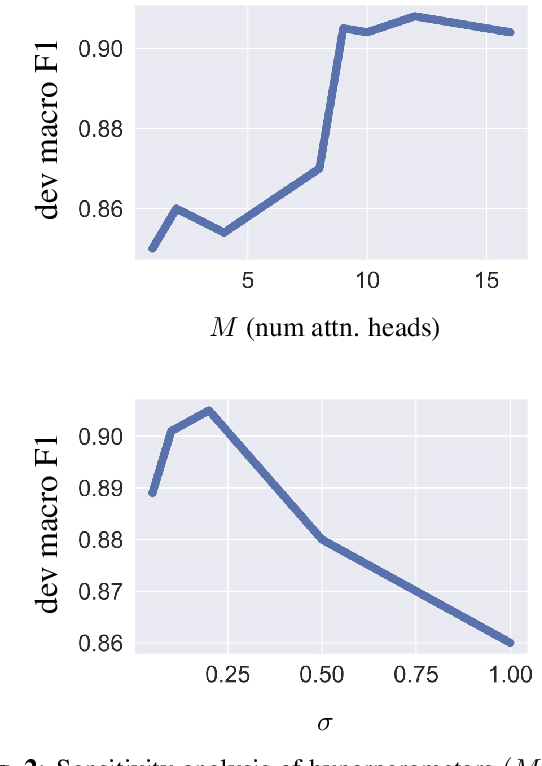
Acoustic Scene Classification (ASC) is a challenging task, as a single scene may involve multiple events that contain complex sound patterns. For example, a cooking scene may contain several sound sources including silverware clinking, chopping, frying, etc. What complicates ASC more is that classes of different activities could have overlapping sounds patterns (e.g. both cooking and dishwashing could have silverware clinking sound). In this paper, we propose a multi-head attention network to model the complex temporal input structures for ASC. The proposed network takes the audio's time-frequency representation as input, and it leverages standard VGG plus LSTM layers to extract high-level feature representation. Further more, it applies multiple attention heads to summarize various patterns of sound events into fixed dimensional representation, for the purpose of final scene classification. The whole network is trained in an end-to-end fashion with back-propagation. Experimental results confirm that our model discovers meaningful sound patterns through the attention mechanism, without using explicit supervision in the alignment. We evaluated our proposed model using DCASE 2018 Task 5 dataset, and achieved competitive performance on par with previous winner's results.