 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Dynamic Knowledge Graph for Visual Semantic Understanding and Applications in Autonomous Robotics
Paper and Code
Sep 16, 2019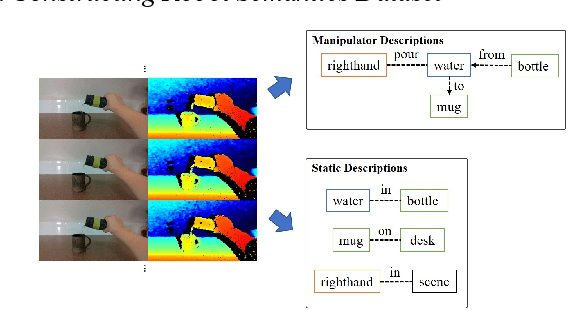
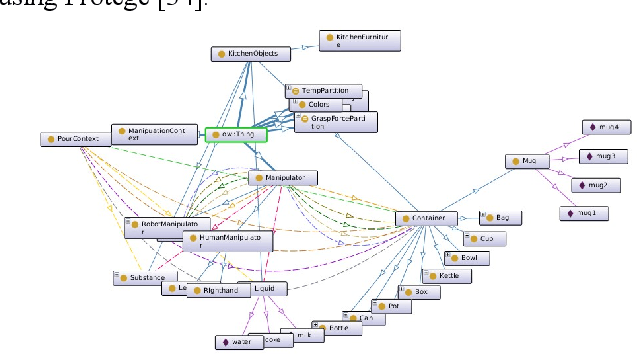

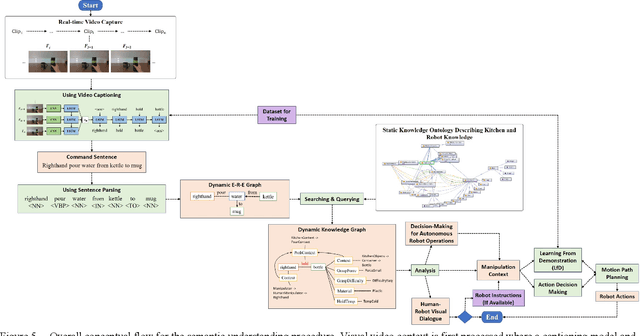
Interpreting semantic knowledge describing entities, relations and attributes explicitly with visuals and implicitly with in behind-scene common senses gain more attention in autonomous robotics. By incorporating vision and language modeling with common-sense knowledge, we can provide rich features indicating strong semantic meanings for human and robot action relationships, which can be utilized further in autonomous robotic controls. In this paper, we propose a systematic scheme to generate high-conceptual dynamic knowledge graphs representing Entity-Relation-Entity (E-R-E) and Entity-Attribute-Value (E-A-V) knowledges by "watching" a video clip. A combination of Vision-Language model and static ontology tree is used to illustrate workspace, configurations, functions and usages for both human and robot. The proposed method is flexible and well-versed. It will serve as our first positioning investigation for further research in various applications for autonomous robots.