 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Noise-Robust Neural Networks via Progressive Adversarial Training
Paper and Code
Sep 17, 2019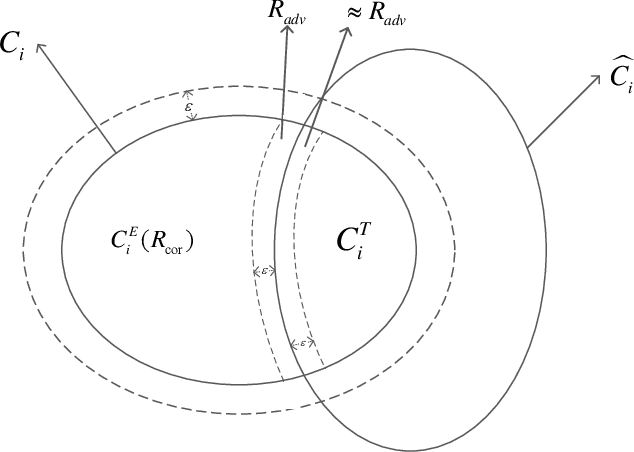
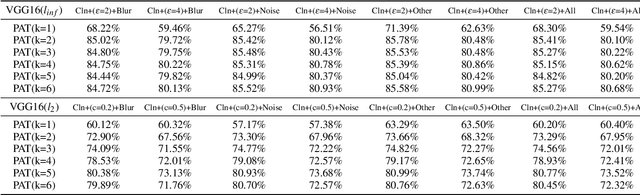
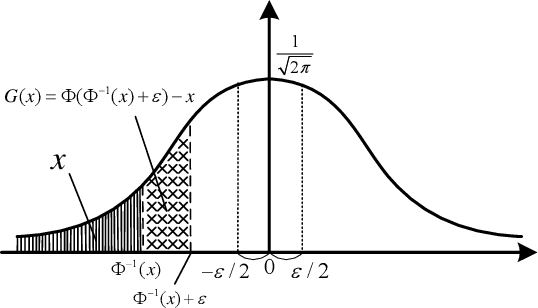
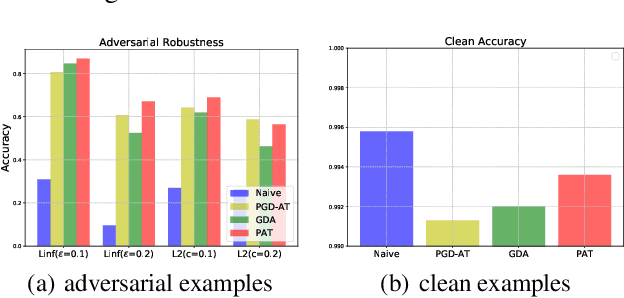
Adversarial examples, intentionally designed inputs tending to mislead deep neural networks, have attracted great attention in the past few years. Although a series of defense strategies have been developed and achieved encouraging model robustness, most of them are still vulnerable to the more commonly witnessed corruptions, e.g., Gaussian noise, blur, etc., in the real world. In this paper, we theoretically and empirically discover the fact that there exists an inherent connection between adversarial robustness and corruption robustness. Based on the fundamental discovery, this paper further proposes a more powerful training method named Progressive Adversarial Training (PAT) that adds diversified adversarial noises progressively during training, and thus obtains robust model against both adversarial examples and corruptions through higher training data complexity. Meanwhile, we also theoretically find that PAT can promise better generalization ability. Experimental evaluation on MNIST, CIFAR-10 and SVHN show that PAT is able to enhance the robustness and generalization of the state-of-the-art network structures, performing comprehensively well compared to various augmentation methods. Moreover, we also propose Mixed Test to evaluate model generalization ability more fairly.