 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prevalence of Errors in Machine Learning Experiments
Paper and Code
Sep 10, 2019

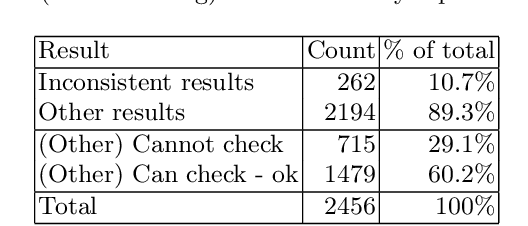
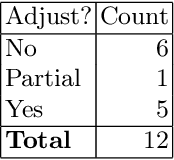
Context: Conducting experiments is central to research machine learning research to benchmark, evaluate and compare learning algorithms. Consequently it is important we conduct reliable, trustworthy experiments. Objective: We investigate the incidence of errors in a sample of machine learning experiments in the domain of software defect prediction. Our focus is simple arithmetical and statistical errors. Method: We analyse 49 papers describing 2456 individual experimental results from a previously undertaken systematic review comparing supervised and unsupervised defect prediction classifiers. We extract the confusion matrices and test for relevant constraints, e.g., the marginal probabilities must sum to one. We also check for multiple statistical significance testing errors. Results: We find that a total of 22 out of 49 papers contain demonstrable errors. Of these 7 were statistical and 16 related to confusion matrix inconsistency (one paper contained both classes of error). Conclusions: Whilst some errors may be of a relatively trivial nature, e.g., transcription errors their presence does not engender confidence. We strongly urge researchers to follow open science principles so errors can be more easily be detected and corrected, thus as a community reduce this worryingly high error rate with our computational experiments.