 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer of Temporal Logic Formulas in Reinforcement Learning
Paper and Code
Sep 10, 2019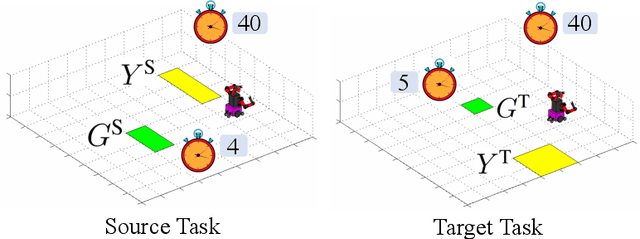
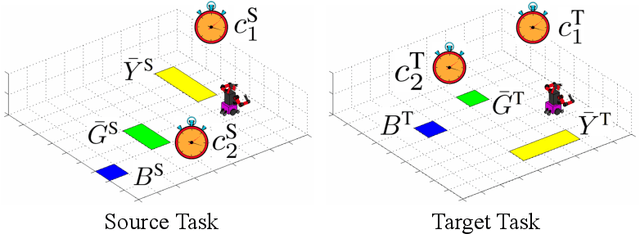

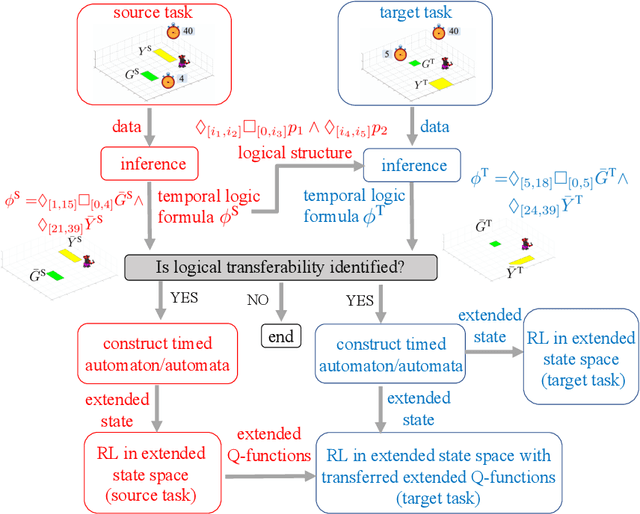
Transferring high-level knowledge from a source task to a target task is an effective way to expedite reinforcement learning (RL). For example, propositional logic and first-order logic have been used as representations of such knowledge. We study the transfer of knowledge between tasks in which the timing of the events matters. We call such tasks temporal tasks. We concretize similarity between temporal tasks through a notion of logical transferability, and develop a transfer learning approach between different yet similar temporal tasks. We first propose an inference technique to extract metric interval temporal logic (MITL) formulas in sequential disjunctive normal form from labeled trajectories collected in RL of the two tasks. If logical transferability is identified through this inference, we construct a timed automaton for each sequential conjunctive subformula of the inferred MITL formulas from both tasks. We perform RL on the extended state which includes the locations and clock valuations of the timed automata for the source task. We then establish mappings between the corresponding components (clocks, locations, etc.) of the timed automata from the two tasks, and transfer the extended Q-functions based on the established mappings. Finally, we perform RL on the extended state for the target task, starting with the transferred extended Q-functions. Our results in two case studies show, depending on how similar the source task and the target task are, that the sampling efficiency for the target task can be improved by up to one order of magnitude by performing RL in the extended state space, and further improved by up to another order of magnitude using the transferred extended Q-functions.