 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Value-Policy Gradients
Paper and Code
Sep 09, 2019
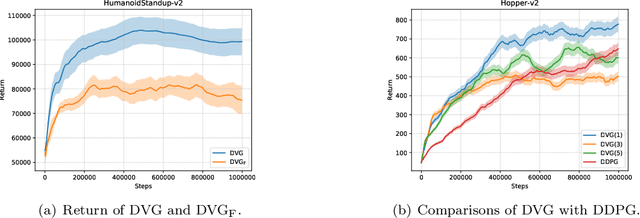
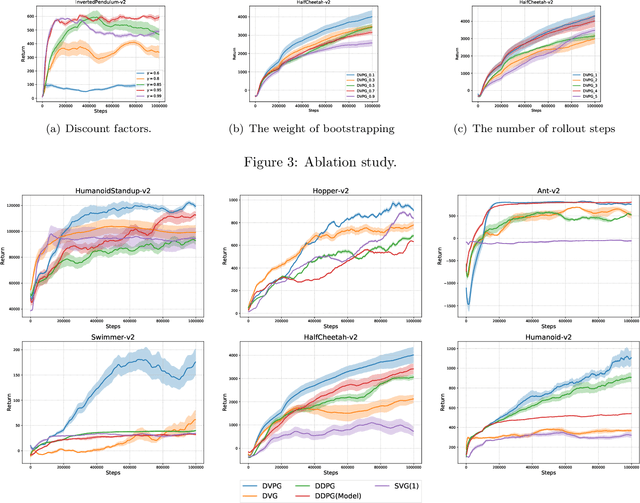
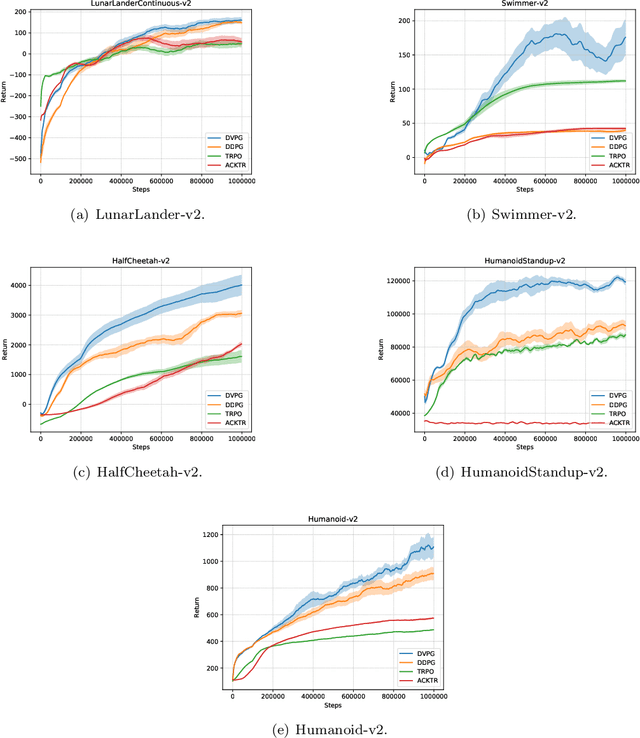
Reinforcement learning algorithms such as the deep deterministic policy gradient algorithm (DDPG) has been widely used in continuous control tasks. However, the model-free DDPG algorithm suffers from high sample complexity. In this paper we consider the deterministic value gradients to improve the sample efficiency of deep reinforcement learning algorithms. Previous works consider deterministic value gradients with the finite horizon, but it is too myopic compared with infinite horizon. We firstly give a theoretical guarantee of the existence of the value gradients in this infinite setting. Based on this theoretical guarantee, we propose a class of the deterministic value gradient algorithm (DVG) with infinite horizon, and different rollout steps of the analytical gradients by the learned model trade off between the variance of the value gradients and the model bias. Furthermore, to better combine the model-based deterministic value gradient estimators with the model-free deterministic policy gradient estimator, we propose the deterministic value-policy gradient (DVPG) algorithm. We finally conduct extensive experiments comparing DVPG with state-of-the-art methods on several standard continuous control benchmarks. Results demonstrate that DVPG substantially outperforms other baselines.