 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMULE: Multimodal Universal Language Embedding
Paper and Code
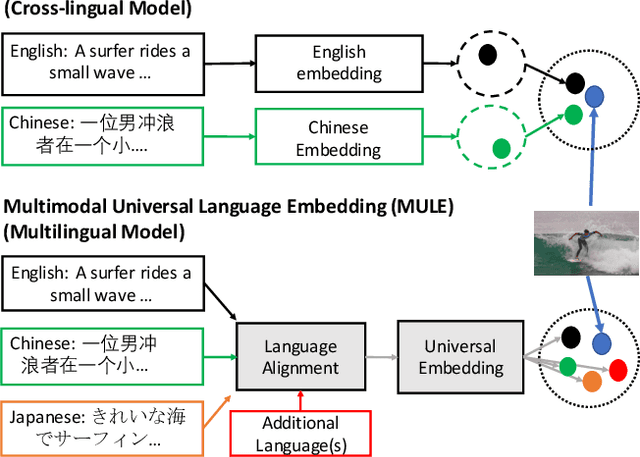
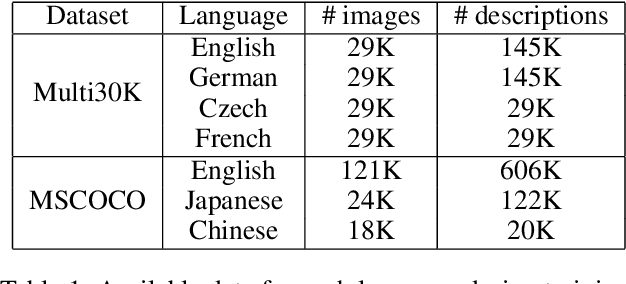
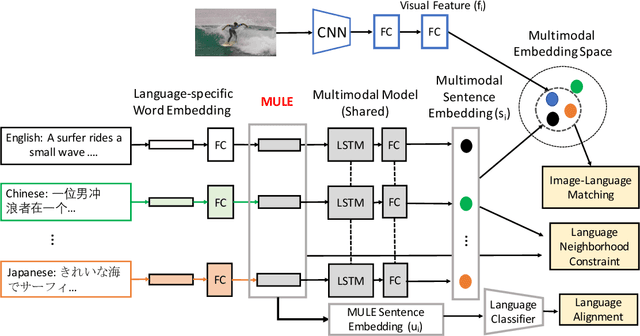
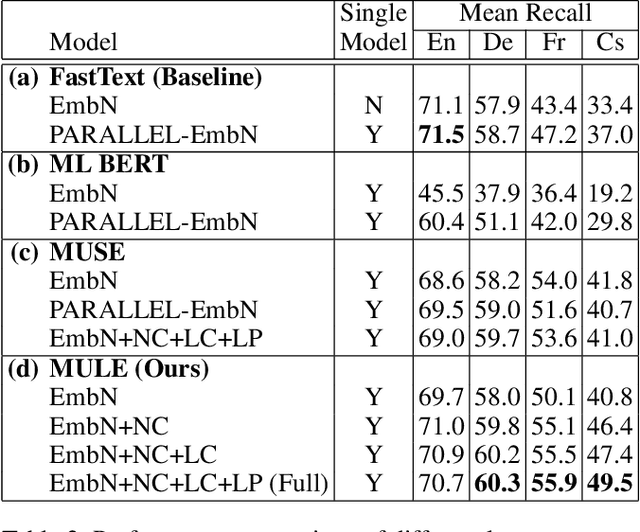
Existing vision-language methods typically support two languages at a time at most. In this paper, we present a modular approach which can easily be incorporated into existing vision-language methods in order to support many languages. We accomplish this by learning a single shared Multimodal Universal Language Embedding (MULE) which has been visually-semantically aligned across all languages. Then we learn to relate the MULE to visual data as if it were a single language. Our method is not architecture specific, unlike prior work which typically learned separate branches for each language, enabling our approach to easily be adapted to many vision-language methods and tasks. Since MULE learns a single language branch in the multimodal model, we can also scale to support many languages, and languages with fewer annotations to take advantage of the good representation learned from other (more abundant) language data. We demonstrate the effectiveness of our embeddings on the bidirectional image-sentence retrieval task, supporting up to four languages in a single model. In addition, we show that Machine Translation can be used for data augmentation in multilingual learning, which, combined with MULE, improves mean recall by up to 20.2% on a single language compared to prior work, with the most significant gains seen on languages with relatively few annotations.