 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEleAtt-RNN: Adding Attentiveness to Neurons in Recurrent Neural Networks
Paper and Code
Sep 03, 2019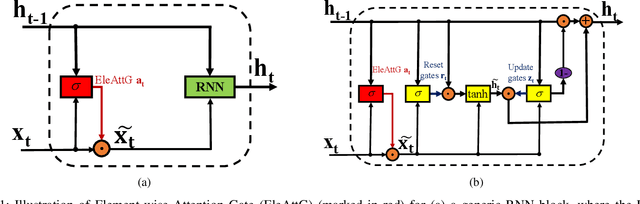
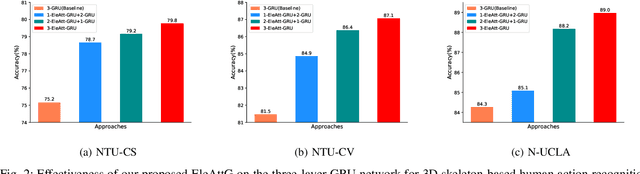


Recurrent neural networks (RNNs) are capable of modeling temporal dependencies of complex sequential data. In general, current available structures of RNNs tend to concentrate on controlling the contributions of current and previous information. However, the exploration of different importance levels of different elements within an input vector is always ignored. We propose a simple yet effective Element-wise-Attention Gate (EleAttG), which can be easily added to an RNN block (e.g. all RNN neurons in an RNN layer), to empower the RNN neurons to have attentiveness capability. For an RNN block, an EleAttG is used for adaptively modulating the input by assigning different levels of importance, i.e., attention, to each element/dimension of the input. We refer to an RNN block equipped with an EleAttG as an EleAtt-RNN block. Instead of modulating the input as a whole, the EleAttG modulates the input at fine granularity, i.e., element-wise, and the modulation is content adaptive. The proposed EleAttG, as an additional fundamental unit, is general and can be applied to any RNN structures, e.g., standard RNN, Long Short-Term Memory (LSTM), or Gated Recurrent Unit (GRU). We demonstrate the effectiveness of the proposed EleAtt-RNN by applying it to different tasks including the action recognition, from both skeleton-based data and RGB videos, gesture recognition, and sequential MNIST classification. Experiments show that adding attentiveness through EleAttGs to RNN blocks significantly improves the power of RNNs.