 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning with Warped Gradient Descent
Paper and Code
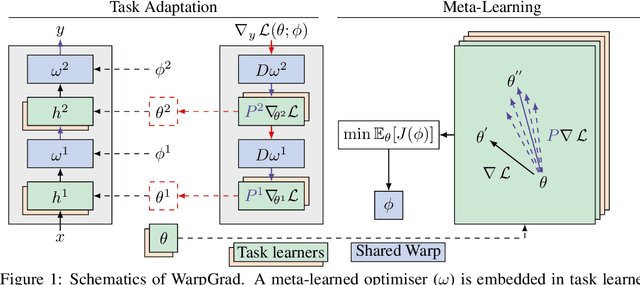
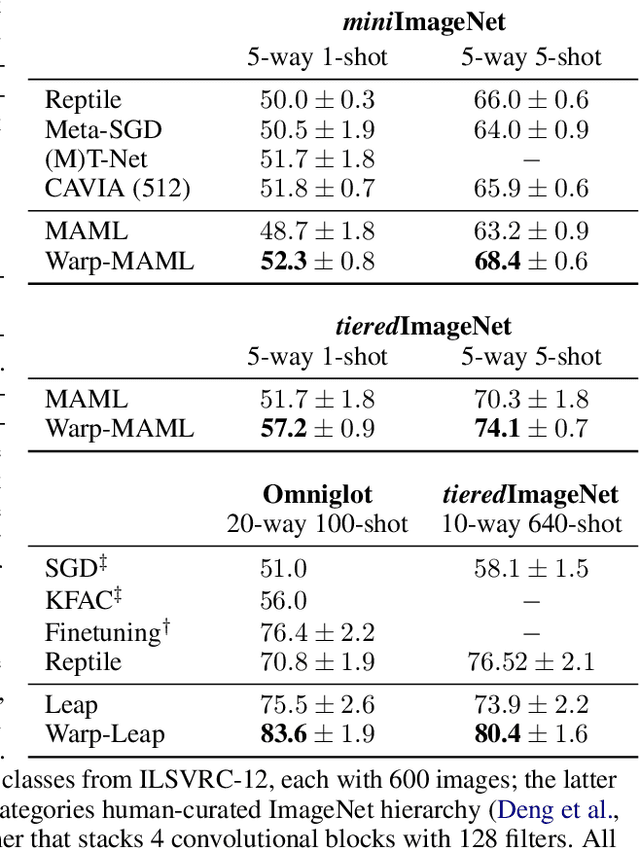
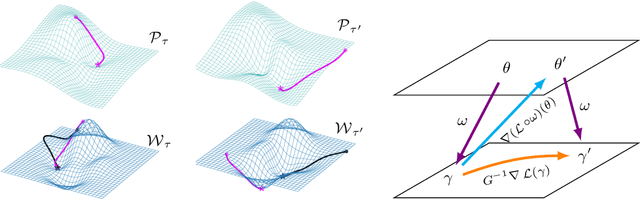
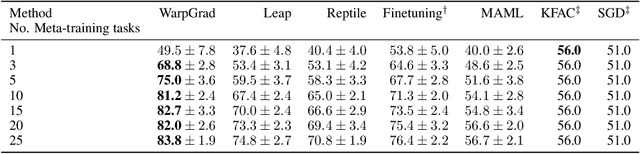
A versatile and effective approach to meta-learning is to infer a gradient-based up-date rule directly from data that promotes rapid learning of new tasks from the same distribution. Current methods rely on backpropagating through the learning process, limiting their scope to few-shot learning. In this work, we introduce Warped Gradient Descent (WarpGrad), a family of modular optimisers that can scale to arbitrary adaptation processes. WarpGrad methods meta-learn to warp task loss surfaces across the joint task-parameter distribution to facilitate gradient descent, which is achieved by a reparametrisation of neural networks that interleaves warp layers in the architecture. These layers are shared across task learners and fixed during adaptation; they represent a projection of task parameters into a meta-learned space that is conducive to task adaptation and standard backpropagation induces a form of gradient preconditioning. WarpGrad methods are computationally efficient and easy to implement as they rely on parameter sharing and backpropagation. They are readily combined with other meta-learners and can scale both in terms of model size and length of adaptation trajectories as meta-learning warp parameters do not require differentiation through task adaptation processes. We show empirically that WarpGrad optimisers meta-learn a warped space where gradient descent is well behaved, with faster convergence and better performance in a variety of settings, including few-shot, standard supervised, continual, and reinforcement learning.