 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreat Ape Detection in Challenging Jungle Camera Trap Footage via Attention-Based Spatial and Temporal Feature Blending
Paper and Code
Aug 29, 2019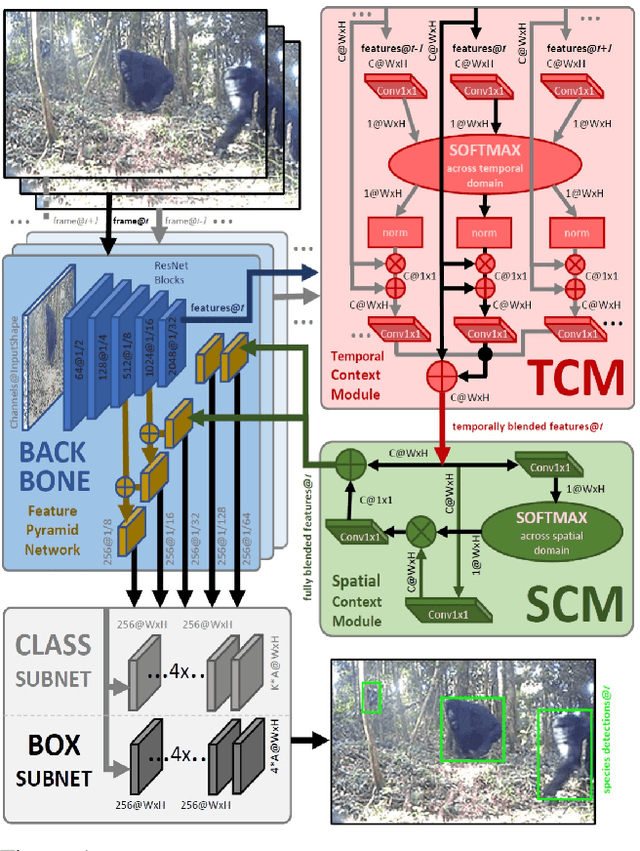
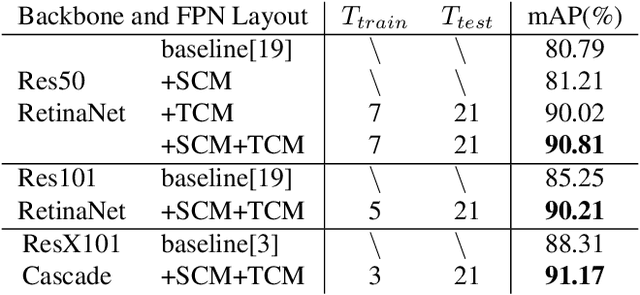

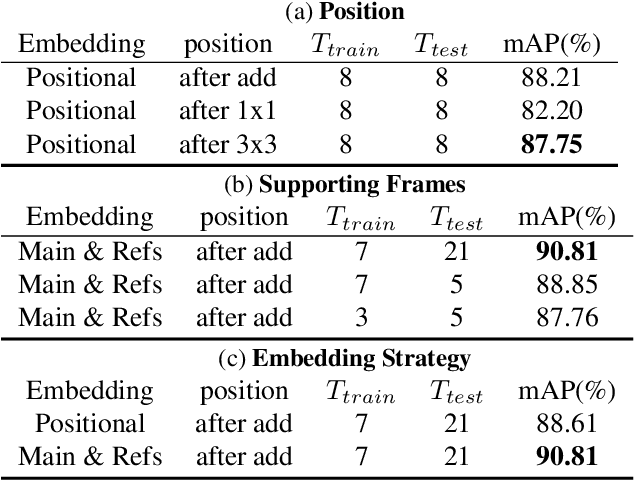
We propose the first multi-frame video object detection framework trained to detect great apes. It is applicable to challenging camera trap footage in complex jungle environments and extends a traditional feature pyramid architecture by adding self-attention driven feature blending in both the spatial as well as the temporal domain. We demonstrate that this extension can detect distinctive species appearance and motion signatures despite significant partial occlusion. We evaluate the framework using 500 camera trap videos of great apes from the Pan African Programme containing 180K frames, which we manually annotated with accurate per-frame animal bounding boxes. These clips contain significant partial occlusions, challenging lighting, dynamic backgrounds, and natural camouflage effects. We show that our approach performs highly robustly and significantly outperforms frame-based detectors. We also perform detailed ablation studies and validation on the full ILSVRC 2015 VID data corpus to demonstrate wider applicability at adequate performance levels. We conclude that the framework is ready to assist human camera trap inspection efforts. We publish code, weights, and ground truth annotations with this paper.