 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation with Atomic Templates for Spoken Language Understanding
Paper and Code
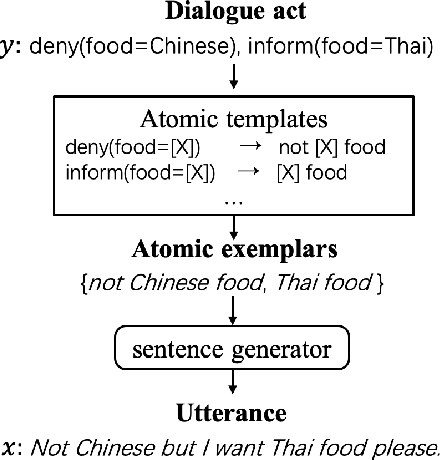
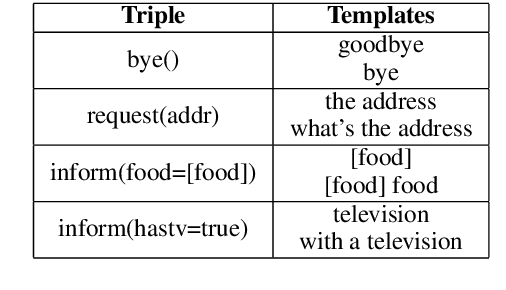
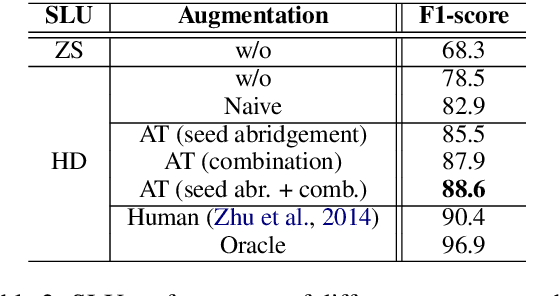
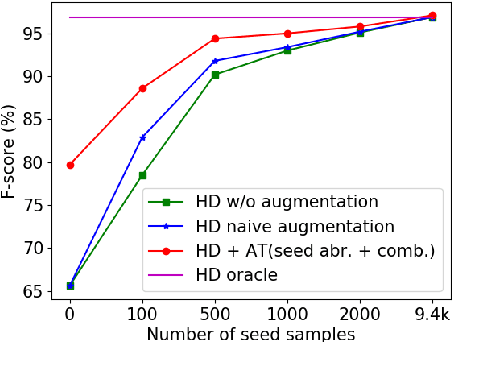
Spoken Language Understanding (SLU) converts user utterances into structured semantic representations. Data sparsity is one of the main obstacles of SLU due to the high cost of human annotation, especially when domain changes or a new domain comes. In this work, we propose a data augmentation method with atomic templates for SLU, which involves minimum human efforts. The atomic templates produce exemplars for fine-grained constituents of semantic representations. We propose an encoder-decoder model to generate the whole utterance from atomic exemplars. Moreover, the generator could be transferred from source domains to help a new domain which has little data. Experimental results show that our method achieves significant improvements on DSTC 2\&3 dataset which is a domain adaptation setting of SLU.