 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Backdoors, Post-Training, in DNN Classifiers via Novel Inference on Optimized Perturbations Inducing Group Misclassification
Paper and Code
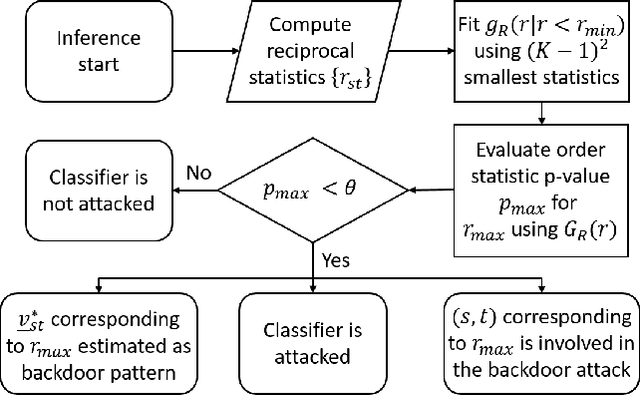
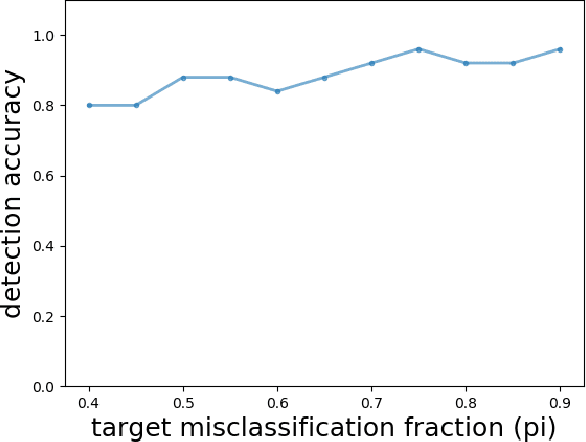
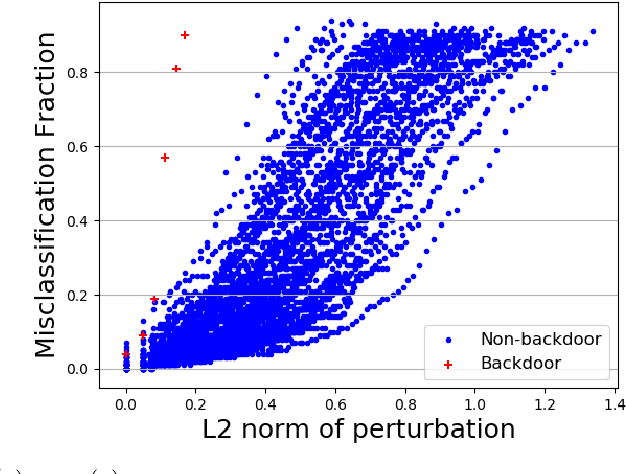
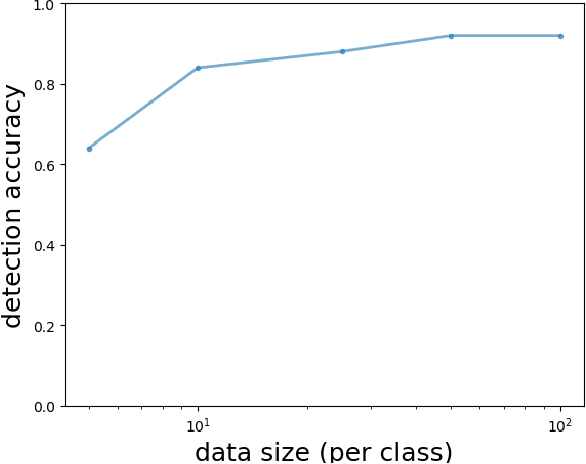
Recently, a special type of data poisoning (DP) attack targeting Deep Neural Network (DNN) classifiers, known as a backdoor, was proposed. These attacks do not seek to degrade classification accuracy, but rather to have the classifier learn to classify to a target class whenever the backdoor pattern is present in a test example. Launching backdoor attacks does not require knowledge of the classifier or its training process - it only needs the ability to poison the training set with (a sufficient number of) exemplars containing a sufficiently strong backdoor pattern (labeled with the target class). Here we address post-training detection of backdoor attacks in DNN image classifiers, seldom considered in existing works, wherein the defender does not have access to the poisoned training set, but only to the trained classifier itself, as well as to clean examples from the classification domain. This is an important scenario because a trained classifier may be the basis of e.g. a phone app that will be shared with many users. Detecting backdoors post-training may thus reveal a widespread attack. We propose a purely unsupervised anomaly detection (AD) defense against imperceptible backdoor attacks that: i) detects whether the trained DNN has been backdoor-attacked; ii) infers the source and target classes involved in a detected attack; iii) we even demonstrate it is possible to accurately estimate the backdoor pattern. We test our AD approach, in comparison with alternative defenses, for several backdoor patterns, data sets, and attack settings and demonstrate its favorability. Our defense essentially requires setting a single hyperparameter (the detection threshold), which can e.g. be chosen to fix the system's false positive rate.