 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnce for All: Train One Network and Specialize it for Efficient Deployment
Paper and Code
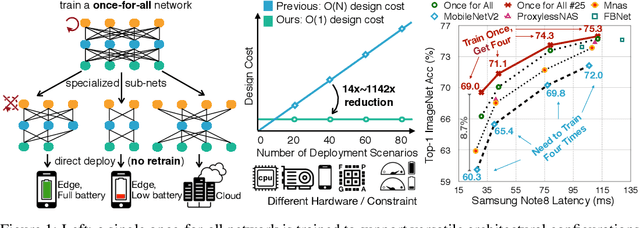
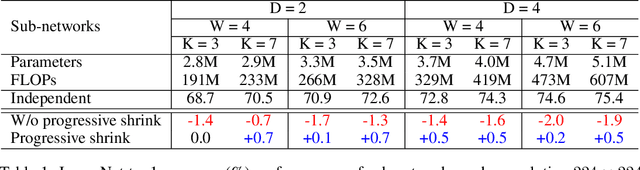
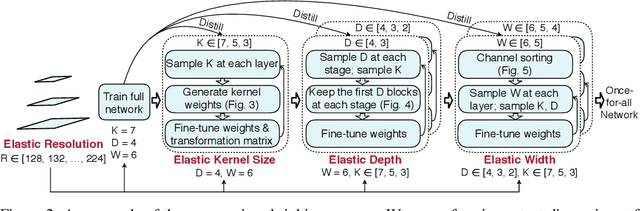
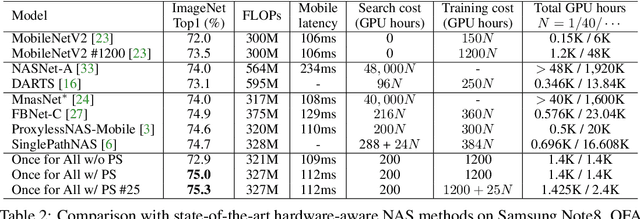
Efficient deployment of deep learning models requires specialized neural network architectures to best fit different hardware platforms and efficiency constraints (defined as deployment scenarios). Traditional approaches either manually design or use AutoML to search a specialized neural network and train it from scratch for each case. It is expensive and unscalable since their training cost is linear w.r.t. the number of deployment scenarios. In this work, we introduce Once for All (OFA) for efficient neural network design to handle many deployment scenarios, a new methodology that decouples model training from architecture search. Instead of training a specialized model for each case, we propose to train a once-for-all network that supports diverse architectural settings (depth, width, kernel size, and resolution). Given a deployment scenario, we can later search a specialized sub-network by selecting from the once-for-all network without training. As such, the training cost of specialized models is reduced from O(N) to O(1). However, it's challenging to prevent interference between many sub-networks. Therefore we propose the progressive shrinking algorithm, which is capable of training a once-for-all network to support more than $10^{19}$ sub-networks while maintaining the same accuracy as independently trained networks, saving the non-recurring engineering (NRE) cost. Extensive experiments on various hardware platforms (Mobile/CPU/GPU) and efficiency constraints show that OFA consistently achieves the same level (or better) ImageNet accuracy than SOTA neural architecture search (NAS) methods. Remarkably, OFA is orders of magnitude faster than NAS in handling multiple deployment scenarios (N). With N=40, OFA requires 14x fewer GPU hours than ProxylessNAS, 16x fewer GPU hours than FBNet and 1,142x fewer GPU hours than MnasNet. The more deployment scenarios, the more savings over NAS.