 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Toxicity in News Articles: Application to Bulgarian
Paper and Code
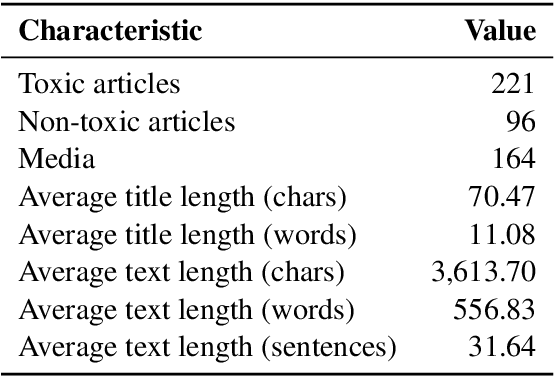
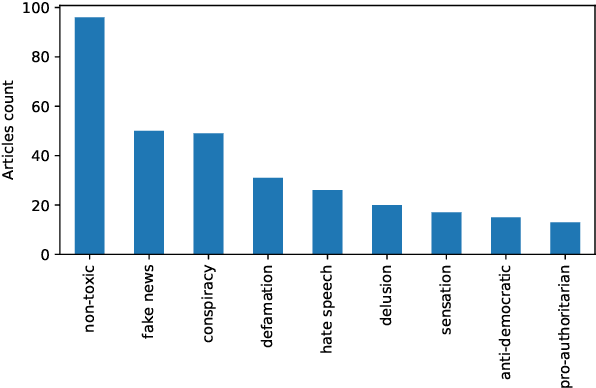
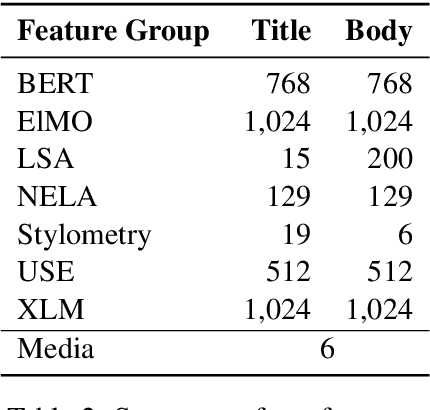
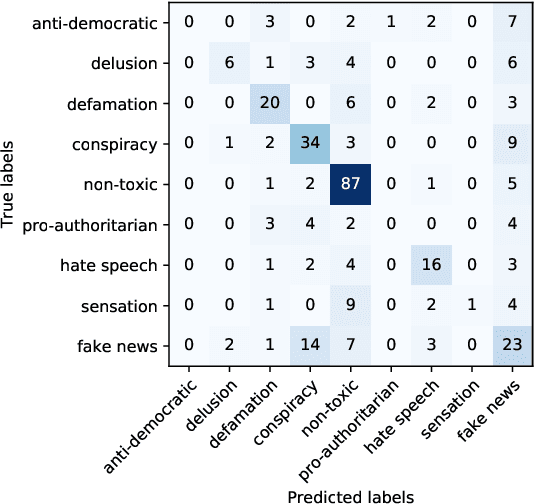
Online media aim for reaching ever bigger audience and for attracting ever longer attention span. This competition creates an environment that rewards sensational, fake, and toxic news. To help limit their spread and impact, we propose and develop a news toxicity detector that can recognize various types of toxic content. While previous research primarily focused on English, here we target Bulgarian. We created a new dataset by crawling a website that for five years has been collecting Bulgarian news articles that were manually categorized into eight toxicity groups. Then we trained a multi-class classifier with nine categories: eight toxic and one non-toxic. We experimented with different representations based on ElMo, BERT, and XLM, as well as with a variety of domain-specific features. Due to the small size of our dataset, we created a separate model for each feature type, and we ultimately combined these models into a meta-classifier. The evaluation results show an accuracy of 59.0% and a macro-F1 score of 39.7%, which represent sizable improvements over the majority-class baseline (Acc=30.3%, macro-F1=5.2%).