 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Defensive Distillation For Defending Text Processing Neural Networks Against Adversarial Examples
Paper and Code
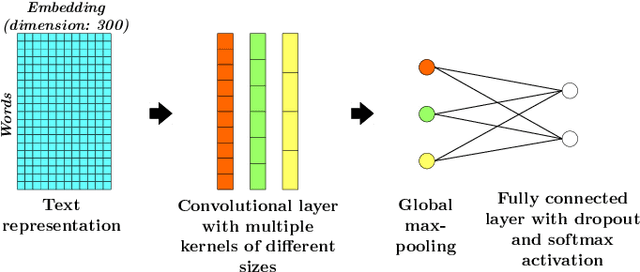


Adversarial examples are artificially modified input samples which lead to misclassifications, while not being detectable by humans. These adversarial examples are a challenge for many tasks such as image and text classification, especially as research shows that many adversarial examples are transferable between different classifiers. In this work, we evaluate the performance of a popular defensive strategy for adversarial examples called defensive distillation, which can be successful in hardening neural networks against adversarial examples in the image domain. However, instead of applying defensive distillation to networks for image classification, we examine, for the first time, its performance on text classification tasks and also evaluate its effect on the transferability of adversarial text examples. Our results indicate that defensive distillation only has a minimal impact on text classifying neural networks and does neither help with increasing their robustness against adversarial examples nor prevent the transferability of adversarial examples between neural networks.