 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Synthesis From Reconfigurable Layout and Style
Paper and Code

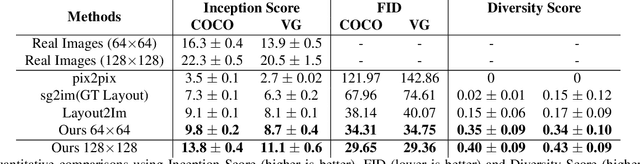
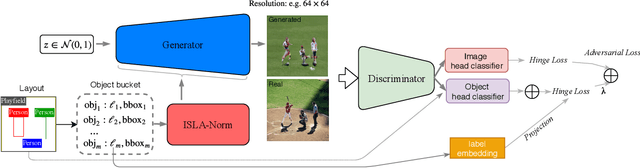
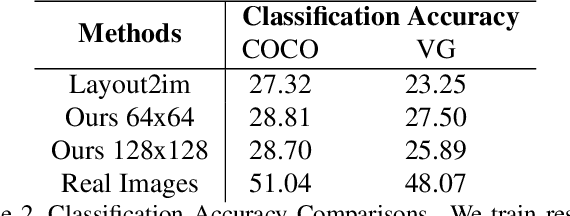
Despite remarkable recent progress on both unconditional and conditional image synthesis, it remains a long-standing problem to learn generative models that are capable of synthesizing realistic and sharp images from reconfigurable spatial layout (i.e., bounding boxes + class labels in an image lattice) and style (i.e., structural and appearance variations encoded by latent vectors), especially at high resolution. By reconfigurable, it means that a model can preserve the intrinsic one-to-many mapping from a given layout to multiple plausible images with different styles, and is adaptive with respect to perturbations of a layout and style latent code. In this paper, we present a layout- and style-based architecture for generative adversarial networks (termed LostGANs) that can be trained end-to-end to generate images from reconfigurable layout and style. Inspired by the vanilla StyleGAN, the proposed LostGAN consists of two new components: (i) learning fine-grained mask maps in a weakly-supervised manner to bridge the gap between layouts and images, and (ii) learning object instance-specific layout-aware feature normalization (ISLA-Norm) in the generator to realize multi-object style generation. In experiments, the proposed method is tested on the COCO-Stuff dataset and the Visual Genome dataset with state-of-the-art performance obtained. The code and pretrained models are available at \url{https://github.com/iVMCL/LostGANs}.