 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuild it Break it Fix it for Dialogue Safety: Robustness from Adversarial Human Attack
Paper and Code
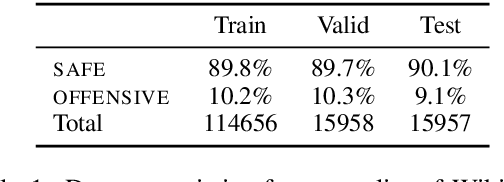
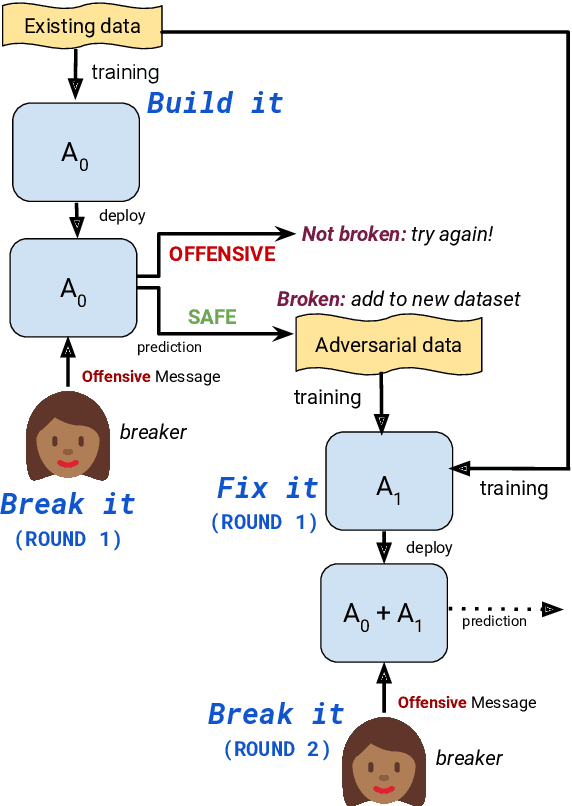


The detection of offensive language in the context of a dialogue has become an increasingly important application of natural language processing. The detection of trolls in public forums (Gal\'an-Garc\'ia et al., 2016), and the deployment of chatbots in the public domain (Wolf et al., 2017) are two examples that show the necessity of guarding against adversarially offensive behavior on the part of humans. In this work, we develop a training scheme for a model to become robust to such human attacks by an iterative build it, break it, fix it strategy with humans and models in the loop. In detailed experiments we show this approach is considerably more robust than previous systems. Further, we show that offensive language used within a conversation critically depends on the dialogue context, and cannot be viewed as a single sentence offensive detection task as in most previous work. Our newly collected tasks and methods will be made open source and publicly available.