 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Validity of Self-Attention as Explanation in Transformer Models
Paper and Code
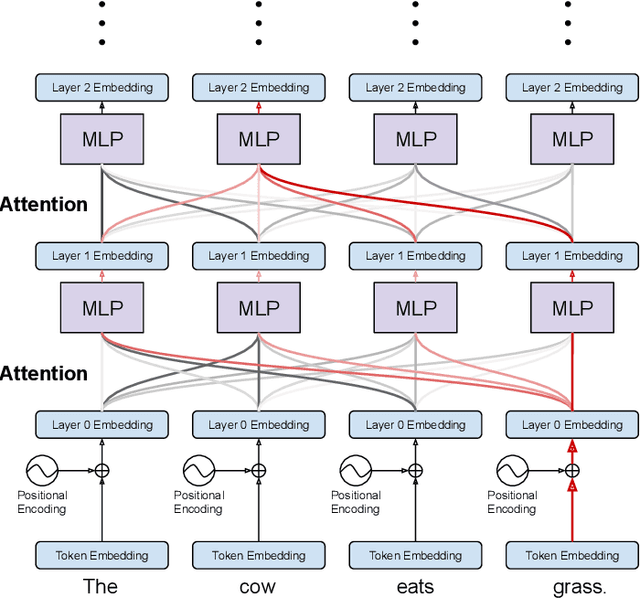
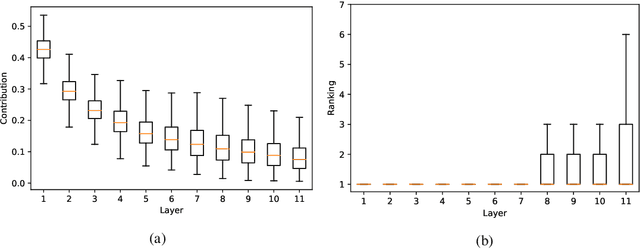
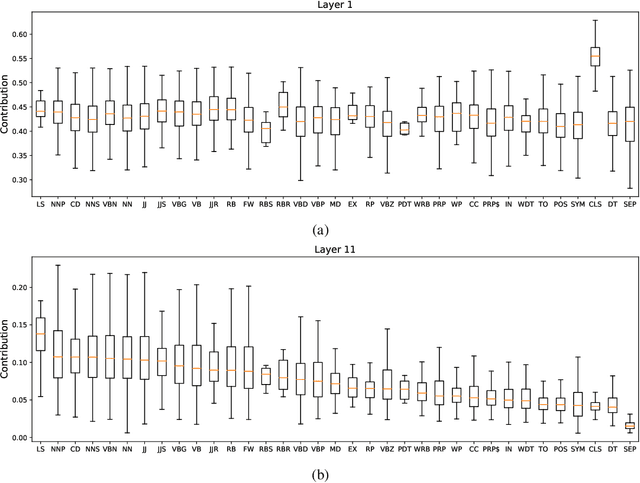
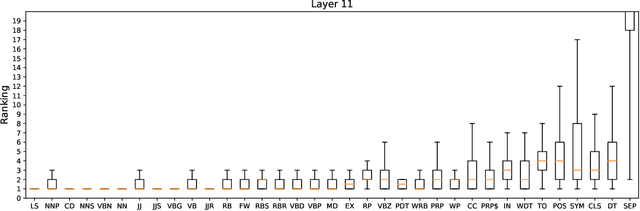
Explainability of deep learning systems is a vital requirement for many applications. However, it is still an unsolved problem. Recent self-attention based models for natural language processing, such as the Transformer or BERT, offer hope of greater explainability by providing attention maps that can be directly inspected. Nevertheless, by just looking at the attention maps one often overlooks that the attention is not over words but over hidden embeddings, which themselves can be mixed representations of multiple embeddings. We investigate to what extent the implicit assumption made in many recent papers - that hidden embeddings at all layers still correspond to the underlying words - is justified. We quantify how much embeddings are mixed based on a gradient based attribution method and find that already after the first layer less than 50% of the embedding is attributed to the underlying word, declining thereafter to a median contribution of 7.5% in the last layer. While throughout the layers the underlying word remains as the one contributing most to the embedding, we argue that attention visualizations are misleading and should be treated with care when explaining the underlying deep learning system.