 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Cross-Lingual Speaker and Phonetic Diversity for Unsupervised Subword Modeling
Paper and Code
Aug 09, 2019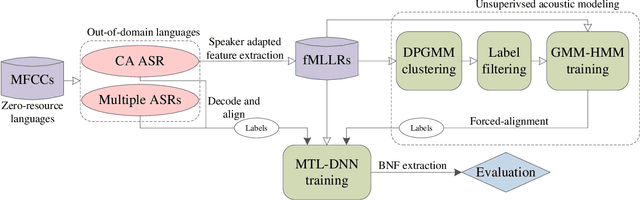
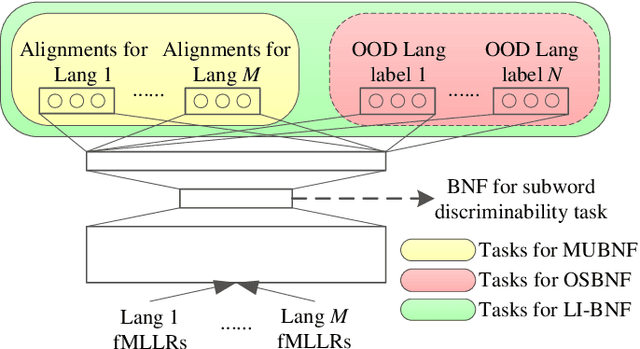
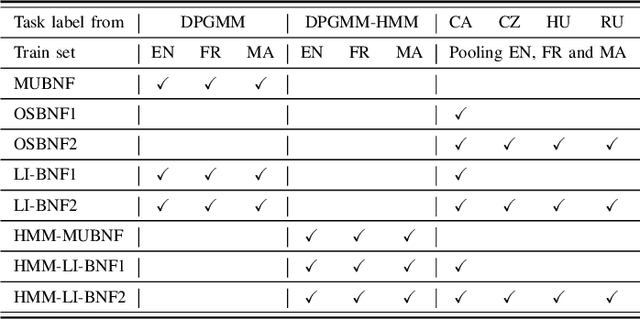
This research addresses the problem of acoustic modeling of low-resource languages for which transcribed training data is absent. The goal is to learn robust frame-level feature representations that can be used to identify and distinguish subword-level speech units. The proposed feature representations comprise various types of multilingual bottleneck features (BNFs) that are obtained via multi-task learning of deep neural networks (MTL-DNN). One of the key problems is how to acquire high-quality frame labels for untranscribed training data to facilitate supervised DNN training. It is shown that learning of robust BNF representations can be achieved by effectively leveraging transcribed speech data and well-trained automatic speech recognition (ASR) systems from one or more out-of-domain (resource-rich) languages. Out-of-domain ASR systems can be applied to perform speaker adaptation with untranscribed training data of the target language, and to decode the training speech into frame-level labels for DNN training. It is also found that better frame labels can be generated by considering temporal dependency in speech when performing frame clustering. The proposed methods of feature learning are evaluated on the standard task of unsupervised subword modeling in Track 1 of the ZeroSpeech 2017 Challenge. The best performance achieved by our system is $9.7\%$ in terms of across-speaker triphone minimal-pair ABX error rate, which is comparable to the best systems reported recently. Lastly, our investigation reveals that the closeness between target languages and out-of-domain languages and the amount of available training data for individual target languages could have significant impact on the goodness of learned features.