 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView N-gram Network for 3D Object Retrieval
Paper and Code
Aug 15, 2019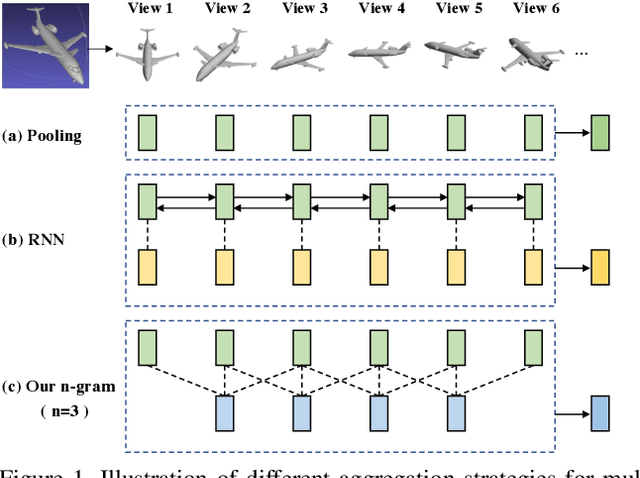
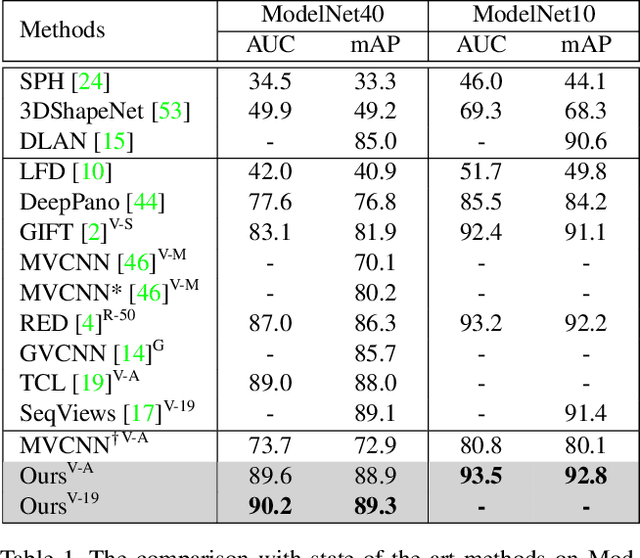
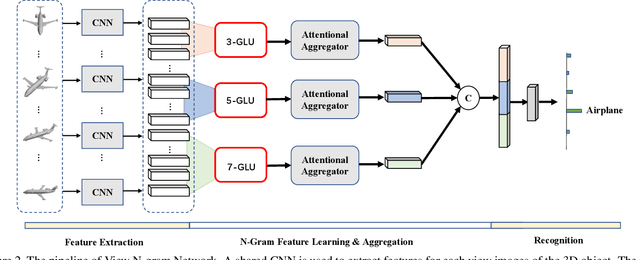
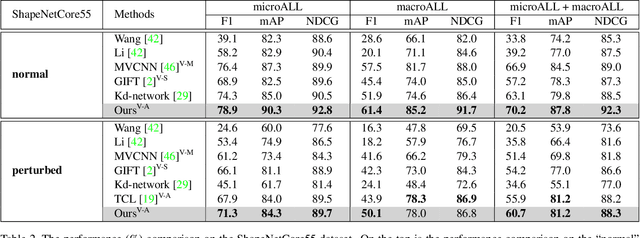
How to aggregate multi-view representations of a 3D object into an informative and discriminative one remains a key challenge for multi-view 3D object retrieval. Existing methods either use view-wise pooling strategies which neglect the spatial information across different views or employ recurrent neural networks which may face the efficiency problem. To address these issues, we propose an effective and efficient framework called View N-gram Network (VNN). Inspired by n-gram models in natural language processing, VNN divides the view sequence into a set of visual n-grams, which involve overlapping consecutive view sub-sequences. By doing so, spatial information across multiple views is captured, which helps to learn a discriminative global embedding for each 3D object. Experiments on 3D shape retrieval benchmarks, including ModelNet10, ModelNet40 and ShapeNetCore55 datasets, demonstrate the superiority of our proposed method.