 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Understanding Catastrophic Forgetting in Continual Learning
Paper and Code
Aug 02, 2019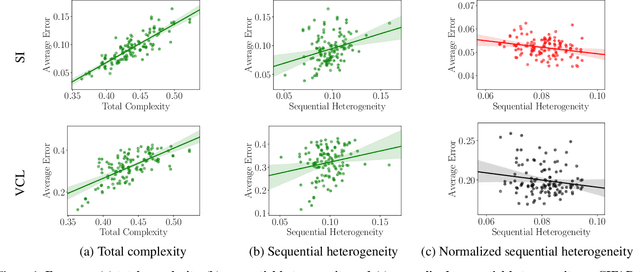
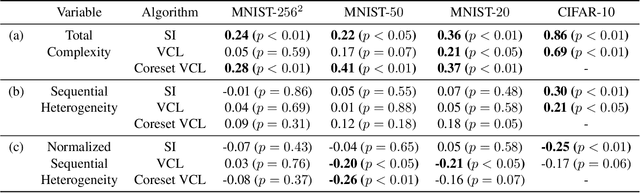
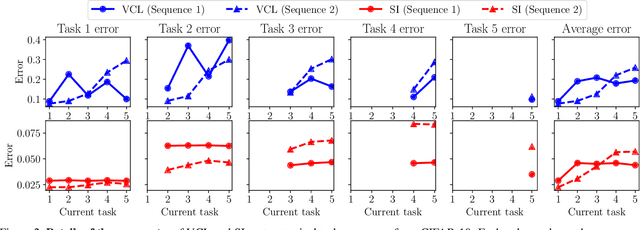
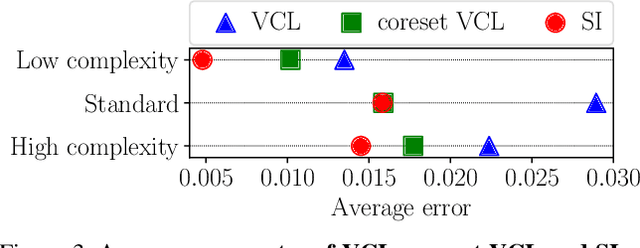
We study the relationship between catastrophic forgetting and properties of task sequences. In particular, given a sequence of tasks, we would like to understand which properties of this sequence influence the error rates of continual learning algorithms trained on the sequence. To this end, we propose a new procedure that makes use of recent developments in task space modeling as well as correlation analysis to specify and analyze the properties we are interested in. As an application, we apply our procedure to study two properties of a task sequence: (1) total complexity and (2) sequential heterogeneity. We show that error rates are strongly and positively correlated to a task sequence's total complexity for some state-of-the-art algorithms. We also show that, surprisingly, the error rates have no or even negative correlations in some cases to sequential heterogeneity. Our findings suggest directions for improving continual learning benchmarks and methods.