 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview and Results: CL-SciSumm Shared Task 2019
Paper and Code
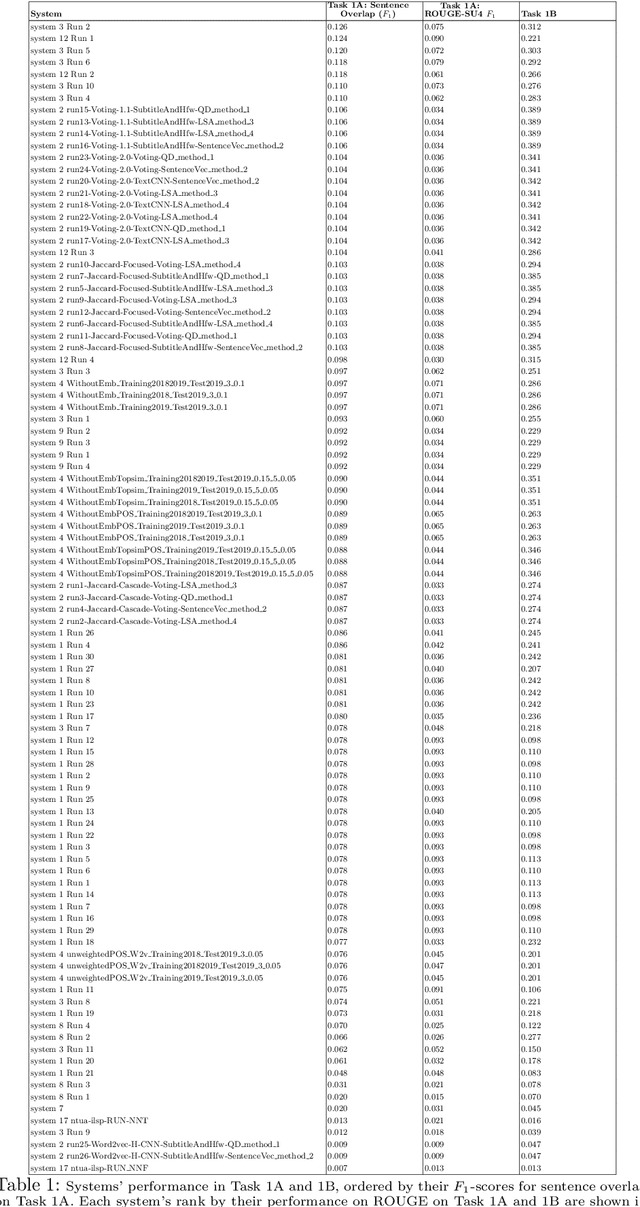
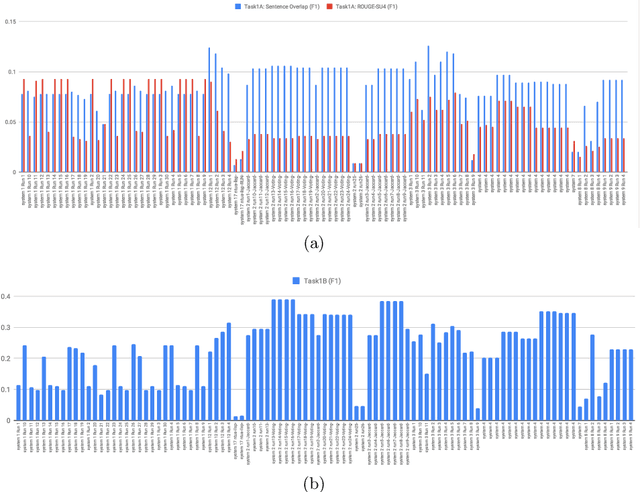
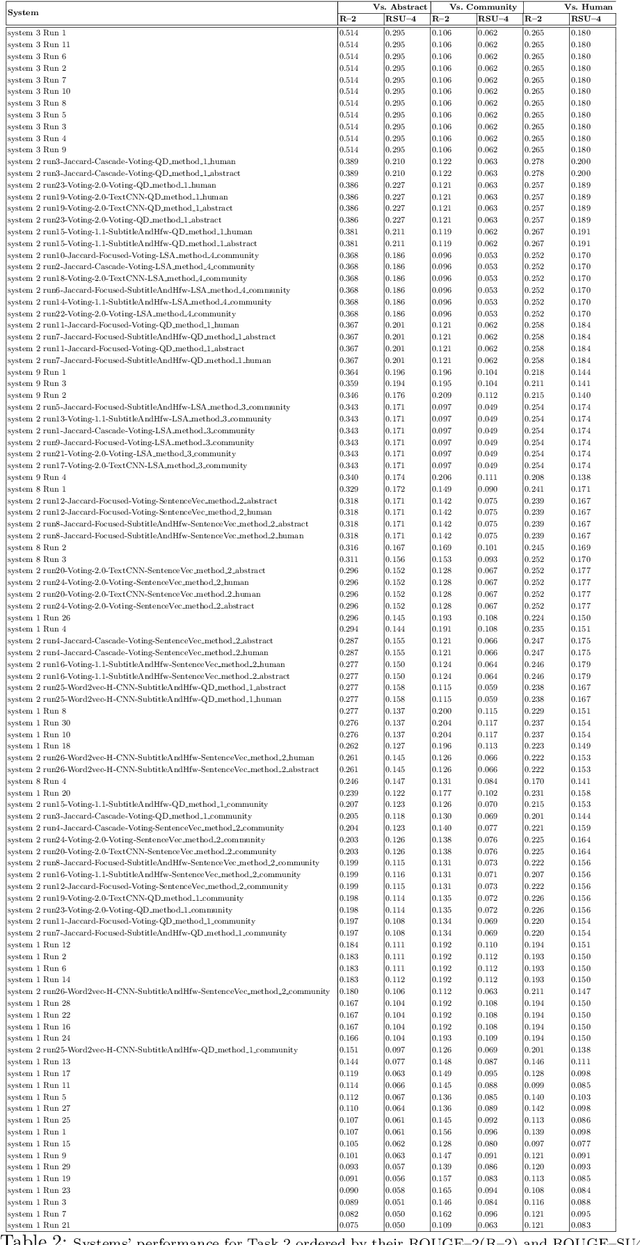
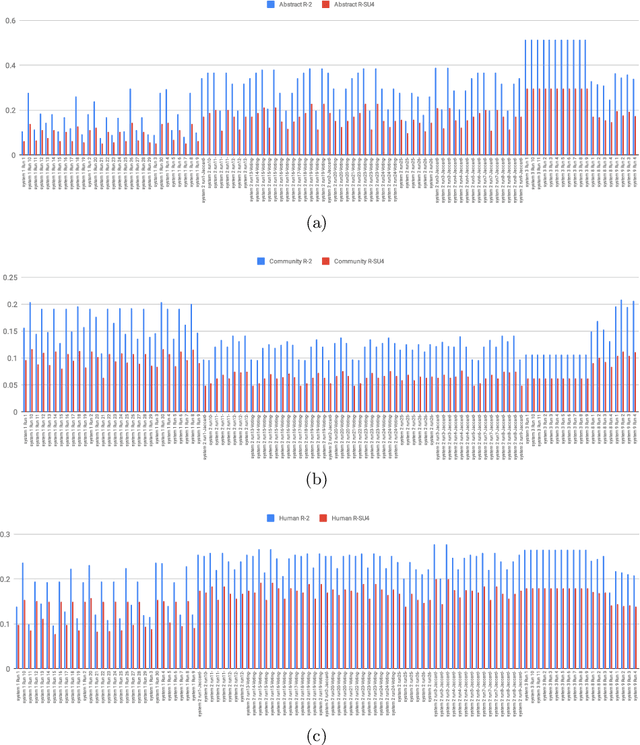
The CL-SciSumm Shared Task is the first medium-scale shared task on scientific document summarization in the computational linguistics~(CL) domain. In 2019, it comprised three tasks: (1A) identifying relationships between citing documents and the referred document, (1B) classifying the discourse facets, and (2) generating the abstractive summary. The dataset comprised 40 annotated sets of citing and reference papers of the CL-SciSumm 2018 corpus and 1000 more from the SciSummNet dataset. All papers are from the open access research papers in the CL domain. This overview describes the participation and the official results of the CL-SciSumm 2019 Shared Task, organized as a part of the 42nd Annual Conference of the Special Interest Group in Information Retrieval (SIGIR), held in Paris, France in July 2019. We compare the participating systems in terms of two evaluation metrics and discuss the use of ROUGE as an evaluation metric. The annotated dataset used for this shared task and the scripts used for evaluation can be accessed and used by the community at: https://github.com/WING-NUS/scisumm-corpus.