 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Focused Attention Network for Image-Text Matching
Paper and Code

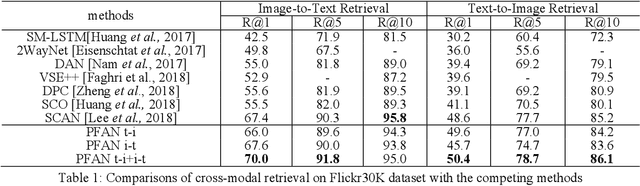
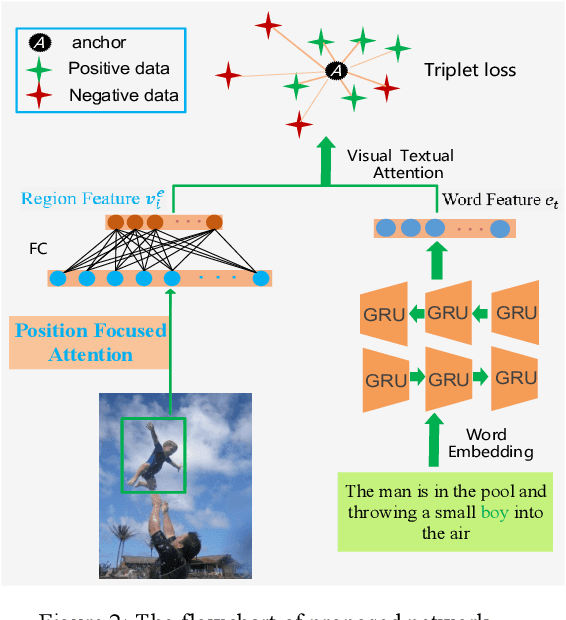
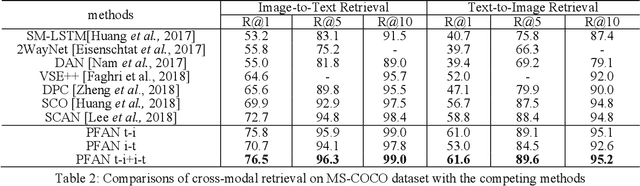
Image-text matching tasks have recently attracted a lot of attention in the computer vision field. The key point of this cross-domain problem is how to accurately measure the similarity between the visual and the textual contents, which demands a fine understanding of both modalities. In this paper, we propose a novel position focused attention network (PFAN) to investigate the relation between the visual and the textual views. In this work, we integrate the object position clue to enhance the visual-text joint-embedding learning. We first split the images into blocks, by which we infer the relative position of region in the image. Then, an attention mechanism is proposed to model the relations between the image region and blocks and generate the valuable position feature, which will be further utilized to enhance the region expression and model a more reliable relationship between the visual image and the textual sentence. Experiments on the popular datasets Flickr30K and MS-COCO show the effectiveness of the proposed method. Besides the public datasets, we also conduct experiments on our collected practical large-scale news dataset (Tencent-News) to validate the practical application value of proposed method. As far as we know, this is the first attempt to test the performance on the practical application. Our method achieves the state-of-art performance on all of these three datasets.