 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D-CTC for Scene Text Recognition
Paper and Code
Jul 23, 2019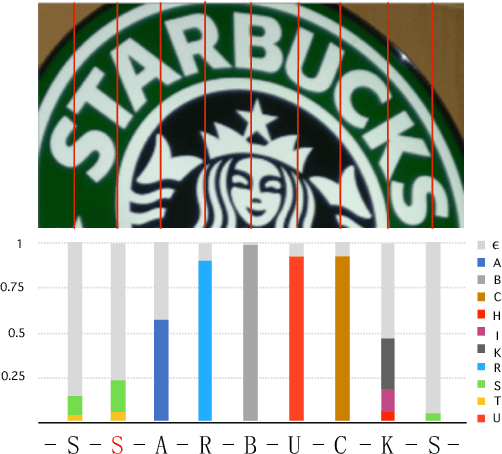
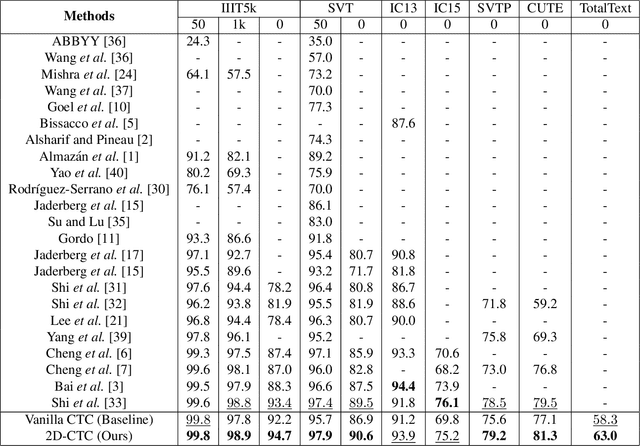
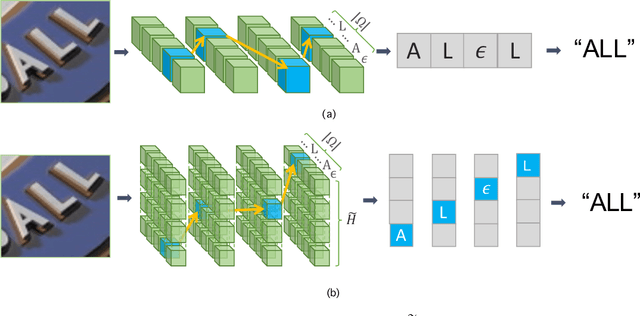

Scene text recognition has been an important, active research topic in computer vision for years. Previous approaches mainly consider text as 1D signals and cast scene text recognition as a sequence prediction problem, by feat of CTC or attention based encoder-decoder framework, which is originally designed for speech recognition. However, different from speech voices, which are 1D signals, text instances are essentially distributed in 2D image spaces. To adhere to and make use of the 2D nature of text for higher recognition accuracy, we extend the vanilla CTC model to a second dimension, thus creating 2D-CTC. 2D-CTC can adaptively concentrate on most relevant features while excluding the impact from clutters and noises in the background; It can also naturally handle text instances with various forms (horizontal, oriented and curved) while giving more interpretable intermediate predictions. The experiments on standard benchmarks for scene text recognition, such as IIIT-5K, ICDAR 2015, SVP-Perspective, and CUTE80, demonstrate that the proposed 2D-CTC model outperforms state-of-the-art methods on the text of both regular and irregular shapes. Moreover, 2D-CTC exhibits its superiority over prior art on training and testing speed. Our implementation and models of 2D-CTC will be made publicly available soon later.