 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighlight Every Step: Knowledge Distillation via Collaborative Teaching
Paper and Code
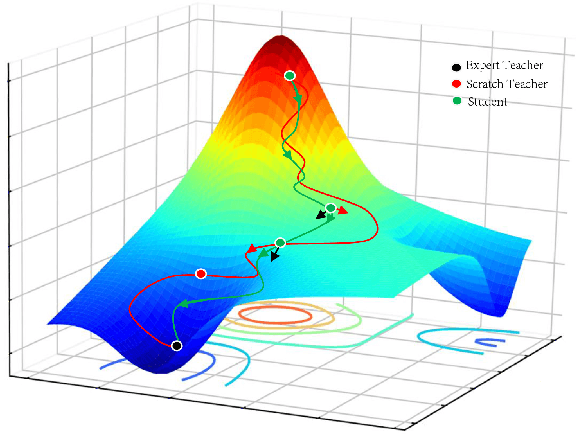
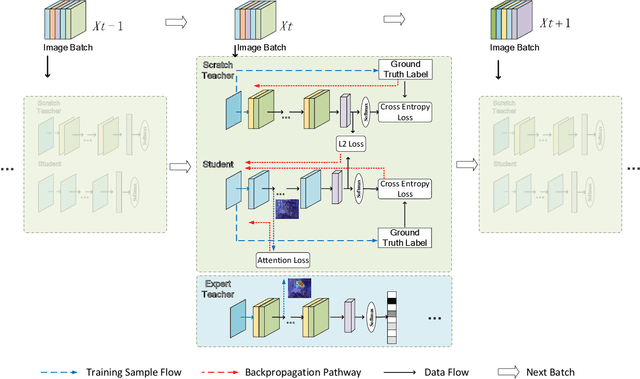

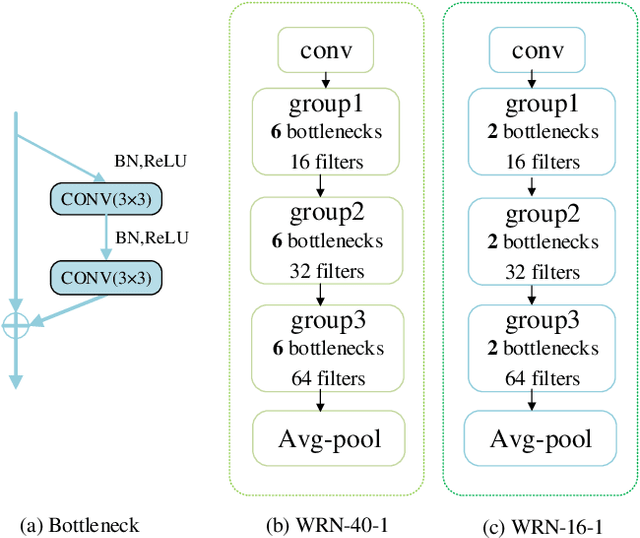
High storage and computational costs obstruct deep neural networks to be deployed on resource-constrained devices. Knowledge distillation aims to train a compact student network by transferring knowledge from a larger pre-trained teacher model. However, most existing methods on knowledge distillation ignore the valuable information among training process associated with training results. In this paper, we provide a new Collaborative Teaching Knowledge Distillation (CTKD) strategy which employs two special teachers. Specifically, one teacher trained from scratch (i.e., scratch teacher) assists the student step by step using its temporary outputs. It forces the student to approach the optimal path towards the final logits with high accuracy. The other pre-trained teacher (i.e., expert teacher) guides the student to focus on a critical region which is more useful for the task. The combination of the knowledge from two special teachers can significantly improve the performance of the student network in knowledge distillation. The results of experiments on CIFAR-10, CIFAR-100, SVHN and Tiny ImageNet datasets verify that the proposed knowledge distillation method is efficient and achieves state-of-the-art performance.