 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Radiology Report Generation based on Multi-view Image Fusion and Medical Concept Enrichment
Paper and Code
Jul 23, 2019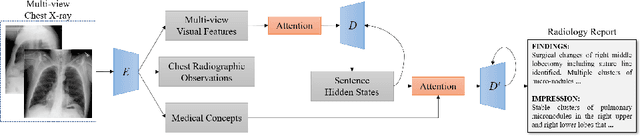

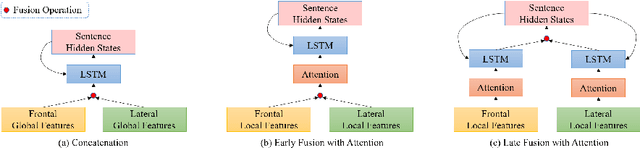
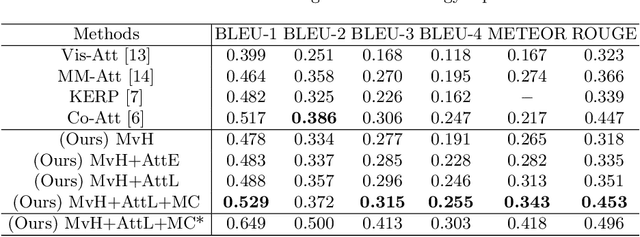
Generating radiology reports is time-consuming and requires extensive expertise in practice. Therefore, reliable automatic radiology report generation is highly desired to alleviate the workload. Although deep learning techniques have been successfully applied to image classification and image captioning tasks, radiology report generation remains challenging in regards to understanding and linking complicated medical visual contents with accurate natural language descriptions. In addition, the data scales of open-access datasets that contain paired medical images and reports remain very limited. To cope with these practical challenges, we propose a generative encoder-decoder model and focus on chest x-ray images and reports with the following improvements. First, we pretrain the encoder with a large number of chest x-ray images to accurately recognize 14 common radiographic observations, while taking advantage of the multi-view images by enforcing the cross-view consistency. Second, we synthesize multi-view visual features based on a sentence-level attention mechanism in a late fusion fashion. In addition, in order to enrich the decoder with descriptive semantics and enforce the correctness of the deterministic medical-related contents such as mentions of organs or diagnoses, we extract medical concepts based on the radiology reports in the training data and fine-tune the encoder to extract the most frequent medical concepts from the x-ray images. Such concepts are fused with each decoding step by a word-level attention model. The experimental results conducted on the Indiana University Chest X-Ray dataset demonstrate that the proposed model achieves the state-of-the-art performance compared with other baseline approaches.