 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2nd Place Solution to the GQA Challenge 2019
Paper and Code
Aug 16, 2019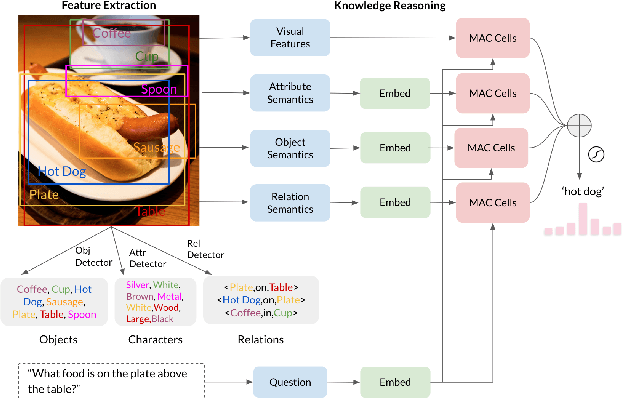
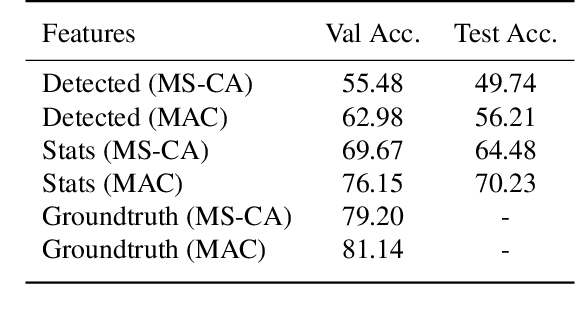
We present a simple method that achieves unexpectedly superior performance for Complex Reasoning involved Visual Question Answering. Our solution collects statistical features from high-frequency words of all the questions asked about an image and use them as accurate knowledge for answering further questions of the same image. We are fully aware that this setting is not ubiquitously applicable, and in a more common setting one should assume the questions are asked separately and they cannot be gathered to obtain a knowledge base. Nonetheless, we use this method as an evidence to demonstrate our observation that the bottleneck effect is more severe on the feature extraction part than it is on the knowledge reasoning part. We show significant gaps when using the same reasoning model with 1) ground-truth features; 2) statistical features; 3) detected features from completely learned detectors, and analyze what these gaps mean to researches on visual reasoning topics. Our model with the statistical features achieves the 2nd place in the GQA Challenge 2019.