Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Incorporation of Speaker Information in Utterance Encoding in Dialog
Paper and Code
Jul 12, 2019

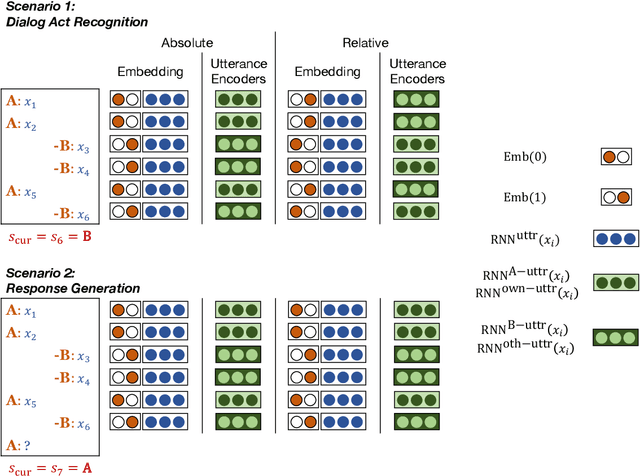
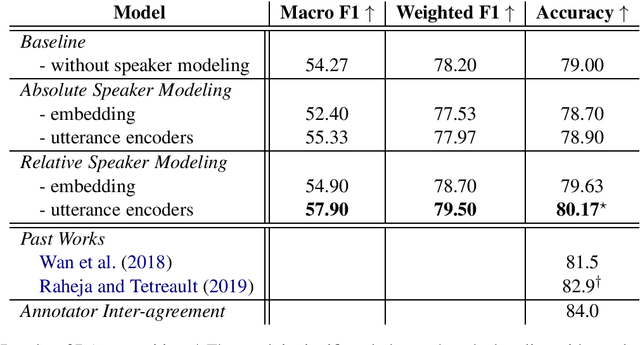
In dialog studies, we often encode a dialog using a hierarchical encoder where each utterance is converted into an utterance vector, and then a sequence of utterance vectors is converted into a dialog vector. Since knowing who produced which utterance is essential to understanding a dialog, conventional methods tried integrating speaker labels into utterance vectors. We found the method problematic in some cases where speaker annotations are inconsistent among different dialogs. A relative speaker modeling method is proposed to address the problem. Experimental evaluations on dialog act recognition and response generation show that the proposed method yields superior and more consistent performances.
* 8+1 pages, 3 figures, and 5 tables. Rejected by SIGDIAL 2019
View paper on