 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular Task-oriented Dialogue System Using a Neural Mixture-of-Experts
Paper and Code
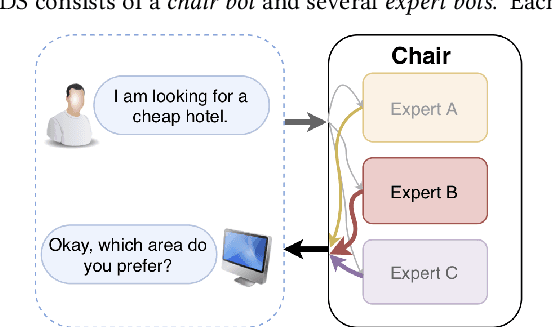

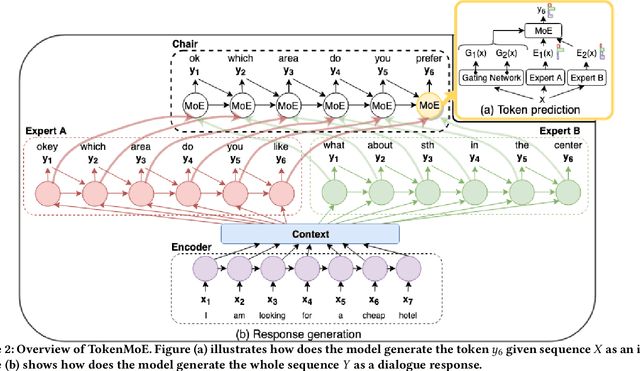
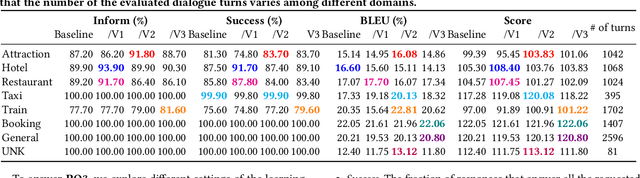
End-to-end Task-oriented Dialogue Systems (TDSs) have attracted a lot of attention for their superiority (e.g., in terms of global optimization) over pipeline modularized TDSs. Previous studies on end-to-end TDSs use a single-module model to generate responses for complex dialogue contexts. However, no model consistently outperforms the others in all cases. We propose a neural Modular Task-oriented Dialogue System(MTDS) framework, in which a few expert bots are combined to generate the response for a given dialogue context. MTDS consists of a chair bot and several expert bots. Each expert bot is specialized for a particular situation, e.g., one domain, one type of action of a system, etc. The chair bot coordinates multiple expert bots and adaptively selects an expert bot to generate the appropriate response. We further propose a Token-level Mixture-of-Expert (TokenMoE) model to implement MTDS, where the expert bots predict multiple tokens at each timestamp and the chair bot determines the final generated token by fully taking into consideration the outputs of all expert bots. Both the chair bot and the expert bots are jointly trained in an end-to-end fashion. To verify the effectiveness of TokenMoE, we carry out extensive experiments on a benchmark dataset. Compared with the baseline using a single-module model, our TokenMoE improves the performance by 8.1% of inform rate and 0.8% of success rate.