 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Action Recognition Via Neural Architecture Searching
Paper and Code
Jul 10, 2019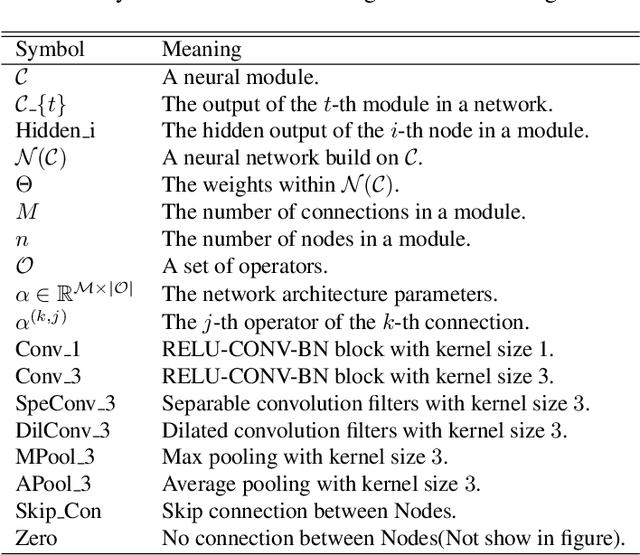
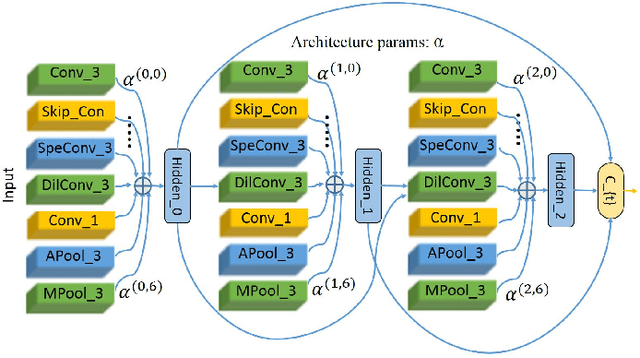
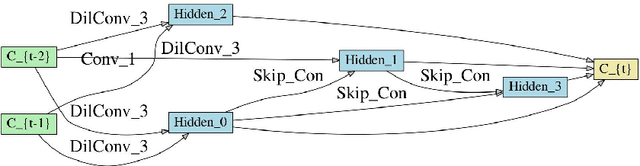
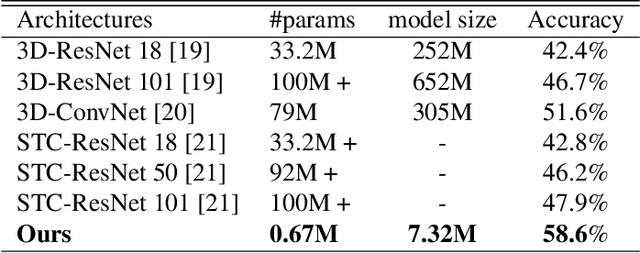
Deep neural networks have achieved great success for video analysis and understanding. However, designing a high-performance neural architecture requires substantial efforts and expertise. In this paper, we make the first attempt to let algorithm automatically design neural networks for video action recognition tasks. Specifically, a spatio-temporal network is developed in a differentiable space modeled by a directed acyclic graph, thus a gradient-based strategy can be performed to search an optimal architecture. Nonetheless, it is computationally expensive, since the computational burden to evaluate each architecture candidate is still heavy. To alleviate this issue, we, for the video input, introduce a temporal segment approach to reduce the computational cost without losing global video information. For the architecture, we explore in an efficient search space by introducing pseudo 3D operators. Experiments show that, our architecture outperforms popular neural architectures, under the training from scratch protocol, on the challenging UCF101 dataset, surprisingly, with only around one percentage of parameters of its manual-design counterparts.