 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of Imitation Learning using GAIL and Reinforcement Learning using Task-achievement Rewards via Probabilistic Generative Model
Paper and Code
Jul 03, 2019
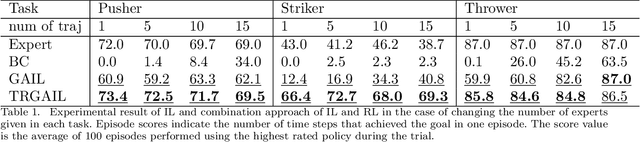
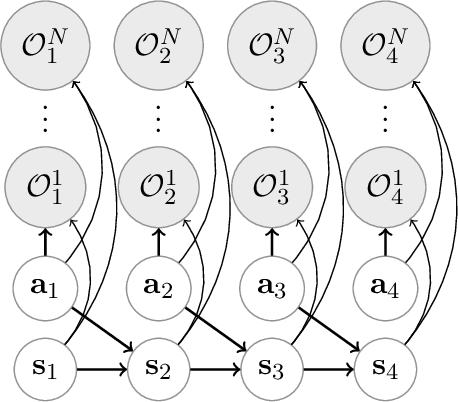
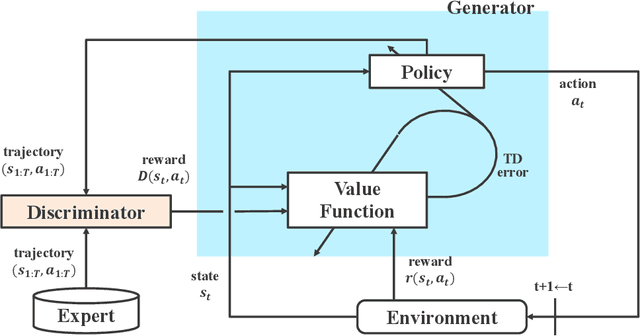
Integration of reinforcement learning and imitation learning is an important problem that has been studied for a long time in the field of intelligent robotics. Reinforcement learning optimizes policies to maximize the cumulative reward, whereas imitation learning attempts to extract general knowledge about the trajectories demonstrated by experts, i.e., demonstrators. Because each of them has their own drawbacks, methods combining them and compensating for each set of drawbacks have been explored thus far. However, many of the methods are heuristic and do not have a solid theoretical basis. In this paper, we present a new theory for integrating reinforcement and imitation learning by extending the probabilistic generative model framework for reinforcement learning, {\it plan by inference}. We develop a new probabilistic graphical model for reinforcement learning with multiple types of rewards and a probabilistic graphical model for Markov decision processes with multiple optimality emissions (pMDP-MO). Furthermore, we demonstrate that the integrated learning method of reinforcement learning and imitation learning can be formulated as a probabilistic inference of policies on pMDP-MO by considering the output of the discriminator in generative adversarial imitation learning as an additional optimal emission observation. We adapt the generative adversarial imitation learning and task-achievement reward to our proposed framework, achieving significantly better performance than agents trained with reinforcement learning or imitation learning alone. Experiments demonstrate that our framework successfully integrates imitation and reinforcement learning even when the number of demonstrators is only a few.