 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Formal Models of Partially Observable Multiagent Decision Making
Paper and Code
Jun 26, 2019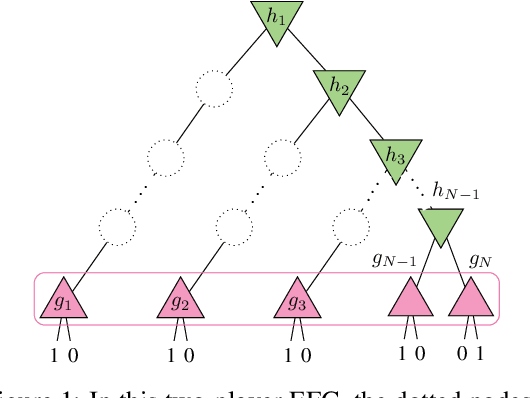
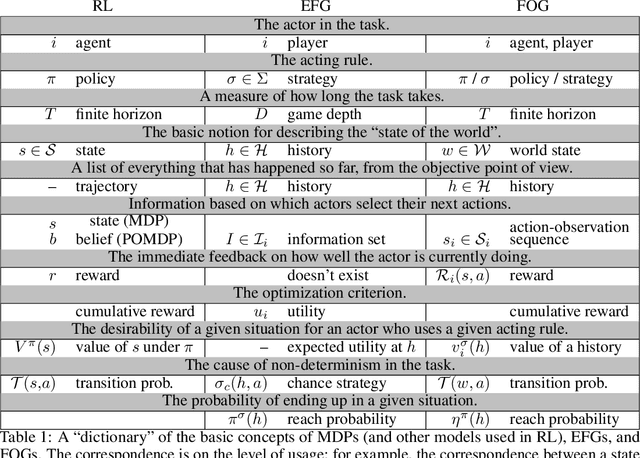
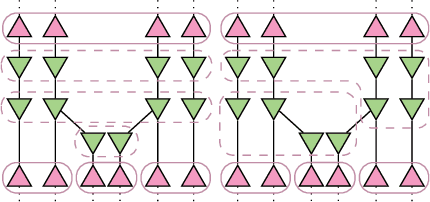
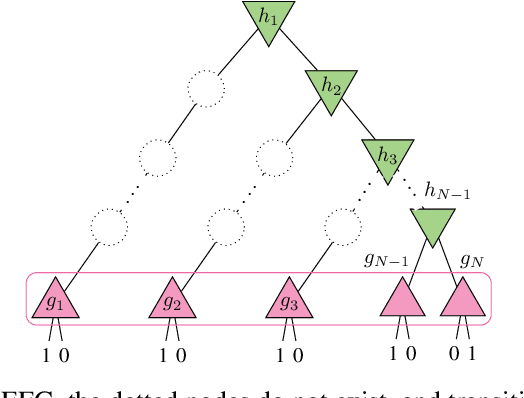
Multiagent decision-making problems in partially observable environments are usually modeled as either extensive-form games (EFGs) within the game theory community or partially observable stochastic games (POSGs) within the reinforcement learning community. While most practical problems can be modeled in both formalisms, the communities using these models are mostly distinct with little sharing of ideas or advances. The last decade has seen dramatic progress in algorithms for EFGs, mainly driven by the challenge problem of poker. We have seen computational techniques achieving super-human performance, some variants of poker are essentially solved, and there are now sound local search algorithms which were previously thought impossible. While the advances have garnered attention, the fundamental advances are not yet understood outside the EFG community. This can be largely explained by the starkly different formalisms between the game theory and reinforcement learning communities and, further, by the unsuitability of the original EFG formalism to make the ideas simple and clear. This paper aims to address these hindrances, by advocating a new unifying formalism, a variant of POSGs, which we call Factored-Observation Games (FOGs). We prove that any timeable perfect-recall EFG can be efficiently modeled as a FOG as well as relating FOGs to other existing formalisms. Additionally, a FOG explicitly identifies the public and private components of observations, which is fundamental to the recent EFG breakthroughs. We conclude by presenting the two building-blocks of these breakthroughs --- counterfactual regret minimization and public state decomposition --- in the new formalism, illustrating our goal of a simpler path for sharing recent advances between game theory and reinforcement learning community.