 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Feasibility of Learning, Rather than Assuming, Human Biases for Reward Inference
Paper and Code
Jun 23, 2019
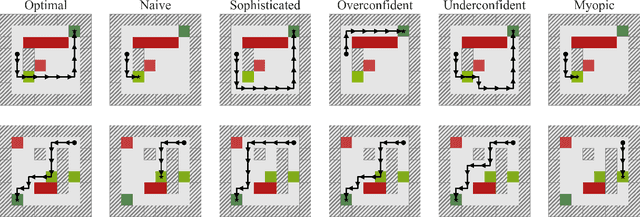
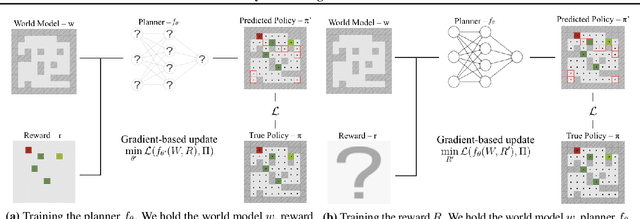
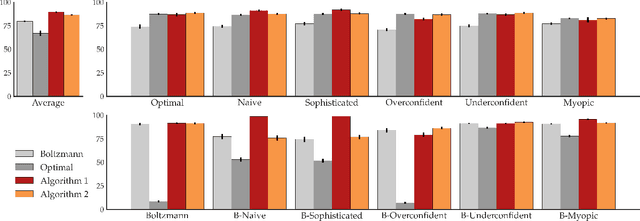
Our goal is for agents to optimize the right reward function, despite how difficult it is for us to specify what that is. Inverse Reinforcement Learning (IRL) enables us to infer reward functions from demonstrations, but it usually assumes that the expert is noisily optimal. Real people, on the other hand, often have systematic biases: risk-aversion, myopia, etc. One option is to try to characterize these biases and account for them explicitly during learning. But in the era of deep learning, a natural suggestion researchers make is to avoid mathematical models of human behavior that are fraught with specific assumptions, and instead use a purely data-driven approach. We decided to put this to the test -- rather than relying on assumptions about which specific bias the demonstrator has when planning, we instead learn the demonstrator's planning algorithm that they use to generate demonstrations, as a differentiable planner. Our exploration yielded mixed findings: on the one hand, learning the planner can lead to better reward inference than relying on the wrong assumption; on the other hand, this benefit is dwarfed by the loss we incur by going from an exact to a differentiable planner. This suggest that at least for the foreseeable future, agents need a middle ground between the flexibility of data-driven methods and the useful bias of known human biases. Code is available at https://tinyurl.com/learningbiases.