 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Data Transformation and Combination for Text Classification
Paper and Code
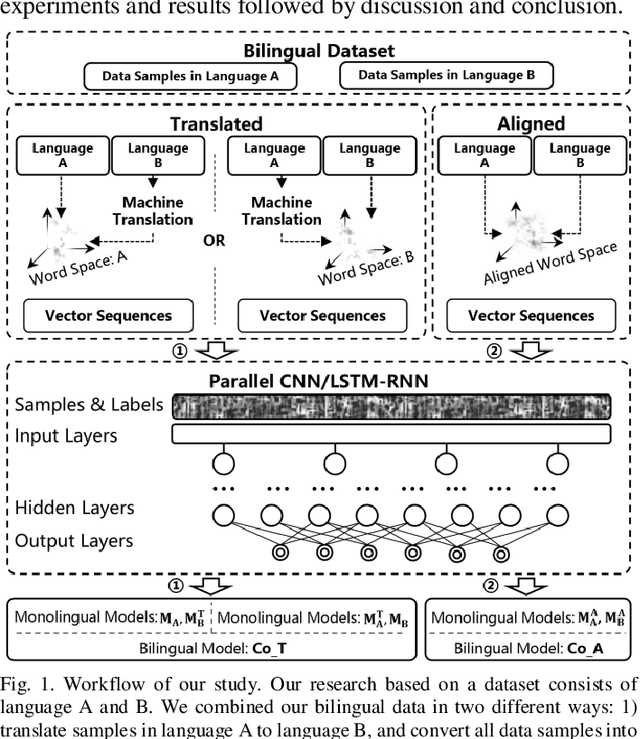
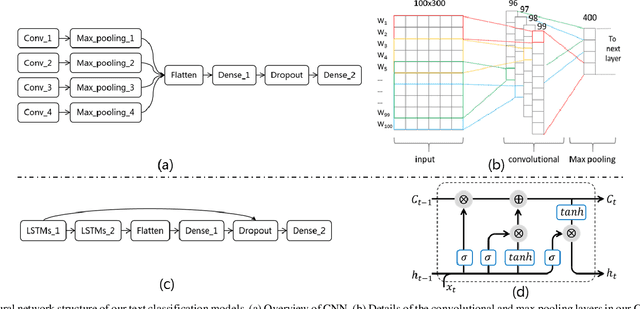
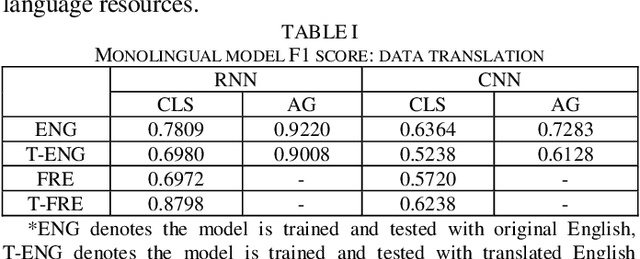
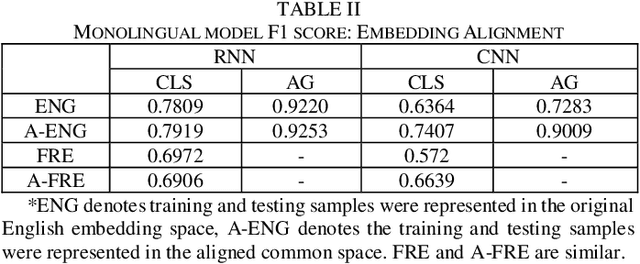
Text classification is a fundamental task for text data mining. In order to train a generalizable model, a large volume of text must be collected. To address data insufficiency, cross-lingual data may occasionally be necessary. Cross-lingual data sources may however suffer from data incompatibility, as text written in different languages can hold distinct word sequences and semantic patterns. Machine translation and word embedding alignment provide an effective way to transform and combine data for cross-lingual data training. To the best of our knowledge, there has been little work done on evaluating how the methodology used to conduct semantic space transformation and data combination affects the performance of classification models trained from cross-lingual resources. In this paper, we systematically evaluated the performance of two commonly used CNN (Convolutional Neural Network) and RNN (Recurrent Neural Network) text classifiers with differing data transformation and combination strategies. Monolingual models were trained from English and French alongside their translated and aligned embeddings. Our results suggested that semantic space transformation may conditionally promote the performance of monolingual models. Bilingual models were trained from a combination of both English and French. Our results indicate that a cross-lingual classification model can significantly benefit from cross-lingual data by learning from translated or aligned embedding spaces.