 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reward Functions by Integrating Human Demonstrations and Preferences
Paper and Code

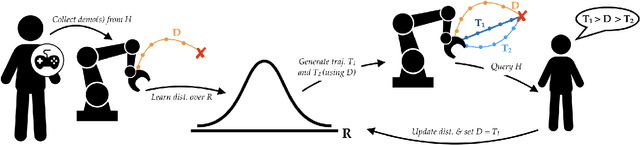
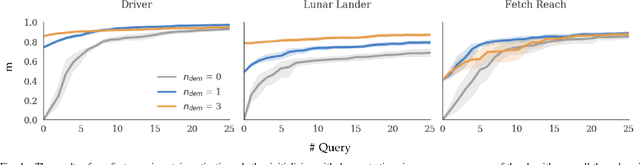
Our goal is to accurately and efficiently learn reward functions for autonomous robots. Current approaches to this problem include inverse reinforcement learning (IRL), which uses expert demonstrations, and preference-based learning, which iteratively queries the user for her preferences between trajectories. In robotics however, IRL often struggles because it is difficult to get high-quality demonstrations; conversely, preference-based learning is very inefficient since it attempts to learn a continuous, high-dimensional function from binary feedback. We propose a new framework for reward learning, DemPref, that uses both demonstrations and preference queries to learn a reward function. Specifically, we (1) use the demonstrations to learn a coarse prior over the space of reward functions, to reduce the effective size of the space from which queries are generated; and (2) use the demonstrations to ground the (active) query generation process, to improve the quality of the generated queries. Our method alleviates the efficiency issues faced by standard preference-based learning methods and does not exclusively depend on (possibly low-quality) demonstrations. In numerical experiments, we find that DemPref is significantly more efficient than a standard active preference-based learning method. In a user study, we compare our method to a standard IRL method; we find that users rated the robot trained with DemPref as being more successful at learning their desired behavior, and preferred to use the DemPref system (over IRL) to train the robot.