 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADA-Tucker: Compressing Deep Neural Networks via Adaptive Dimension Adjustment Tucker Decomposition
Paper and Code
Jun 18, 2019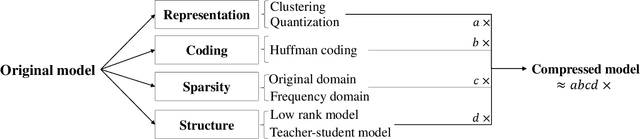
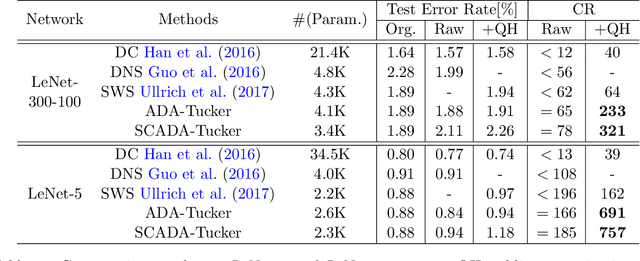
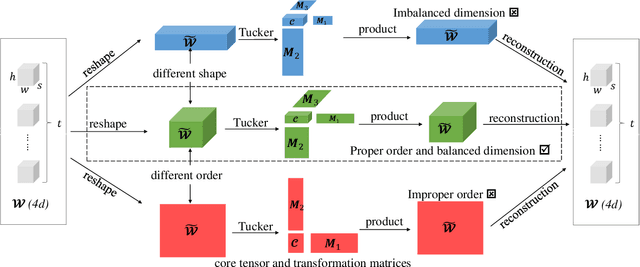

Despite the recent success of deep learning models in numerous applications, their widespread use on mobile devices is seriously impeded by storage and computational requirements. In this paper, we propose a novel network compression method called Adaptive Dimension Adjustment Tucker decomposition (ADA-Tucker). With learnable core tensors and transformation matrices, ADA-Tucker performs Tucker decomposition of arbitrary-order tensors. Furthermore, we propose that weight tensors in networks with proper order and balanced dimension are easier to be compressed. Therefore, the high flexibility in decomposition choice distinguishes ADA-Tucker from all previous low-rank models. To compress more, we further extend the model to Shared Core ADA-Tucker (SCADA-Tucker) by defining a shared core tensor for all layers. Our methods require no overhead of recording indices of non-zero elements. Without loss of accuracy, our methods reduce the storage of LeNet-5 and LeNet-300 by ratios of 691 times and 233 times, respectively, significantly outperforming state of the art. The effectiveness of our methods is also evaluated on other three benchmarks (CIFAR-10, SVHN, ILSVRC12) and modern newly deep networks (ResNet, Wide-ResNet).